






NI BLOG
ネイチャーインサイト株式会社の情報発信ブログ
SASに関する技術情報など





Lakeflow Spark 宣言型パイプラインのチュートリアルを動かしてみました
はじめに
データアナリティクス部の大貫です。
Databricks には Lakeflow Spark 宣言型パイプライン(以下、SDP)という機能があります。簡単にパイプラインを開発できる機能なのですが、私は業務ではほとんど使用したことがなく、あまり馴染みのない機能でした。
しかし、SDPのチュートリアルを動かしてみたところ、どのような機能かイメージが付き、説明を読むだけではなく、実際に手を動かしてみることは非常に重要だなと改めて感じました。
そこで今回の記事では、SDPのチュートリアルの動かし方と、SDPがどのような機能か簡単にご紹介したいと思います。
ちなみに、SDP は Databricks Certified Data Engineer Professional の試験範囲となっています。(試験ガイドはこちらです。)
本記事では下記について記載していきたいと思います。
- SDPについて
- SDPチュートリアル
- 手順1:パイプラインの作成
- 手順2:データ品質チェックを適用する
- 手順3:上位のユーザーを分析する
- 感想
- まとめ
本記事は執筆時点(2026年6月時点)での内容です。
SDPについて
- 概要
SDPは、SQLおよびPythonでバッチおよびストリーミング データ パイプラインを開発および実行するための宣言型フレームワークです。
簡単に言うと、『どう処理するか(手順)』を細かく書かなくても、『どんなデータが欲しいか(完成図)』を伝えるだけで、後はDatabricksが勝手に裏側を整えてくれる賢い仕組みです。
- メリット
- こちらにSDPのメリットが3つ挙げられています。
- 自動オーケストレーション
- テーブルの依存関係を理解し、処理の順番や効率を自動で最適化してくれます。
- タスクが失敗しても自動的かつ効率的に再試行してくれます。
- 宣言型処理
- どういうデータが欲しいかを関数で定義するだけで、後は自動でやってくれます。
- 「AUTO CDC API」という機能を使えば、テーブルの履歴管理(SCD タイプ1/2)も自動で簡単にやってくれます。
- 増分処理
- 可能な限り新しいデータと変更のあったデータだけ処理してくれます。
- これにより非効率的な再処理が減り、増分処理をする手動コードが不要になります。
- 自動オーケストレーション
- こちらにSDPのメリットが3つ挙げられています。
SDPチュートリアル
- チュートリアルについて
こちらに記載のチュートリアルを実際にやってみます。
実行するための前提条件が書かれていますので、もし上手くいかない場合は確認してみてください。
手順1:パイプラインの作成
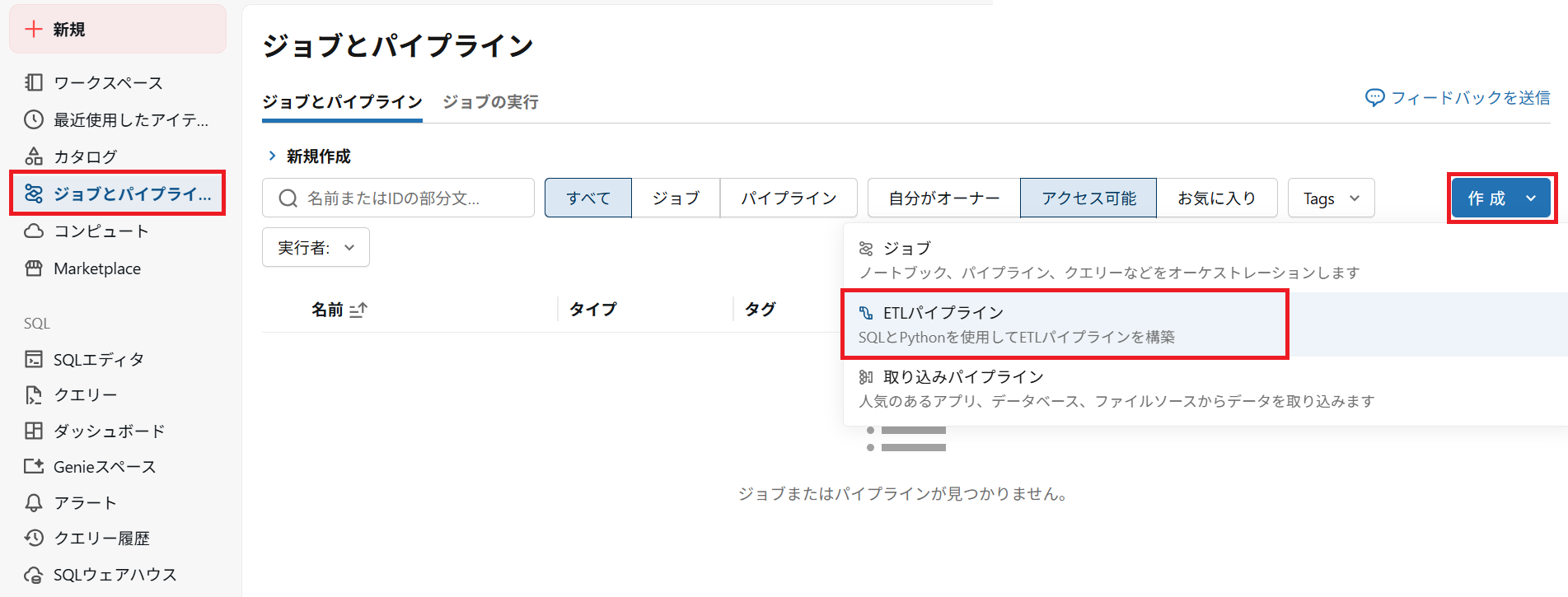
1.作成
1.1.「ジョブとパイプライン」を選択
1.2.「作成」を選択
1.3.「ETLパイプライン」を選択
2.パイプライン名の変更
- チュートリアルでは、作成されるテーブル名にパイプライン名が反映される設定になっています。テーブル名に日本語が入っているとエラーになるので、パイプライン名はアルファベットで命名してください。
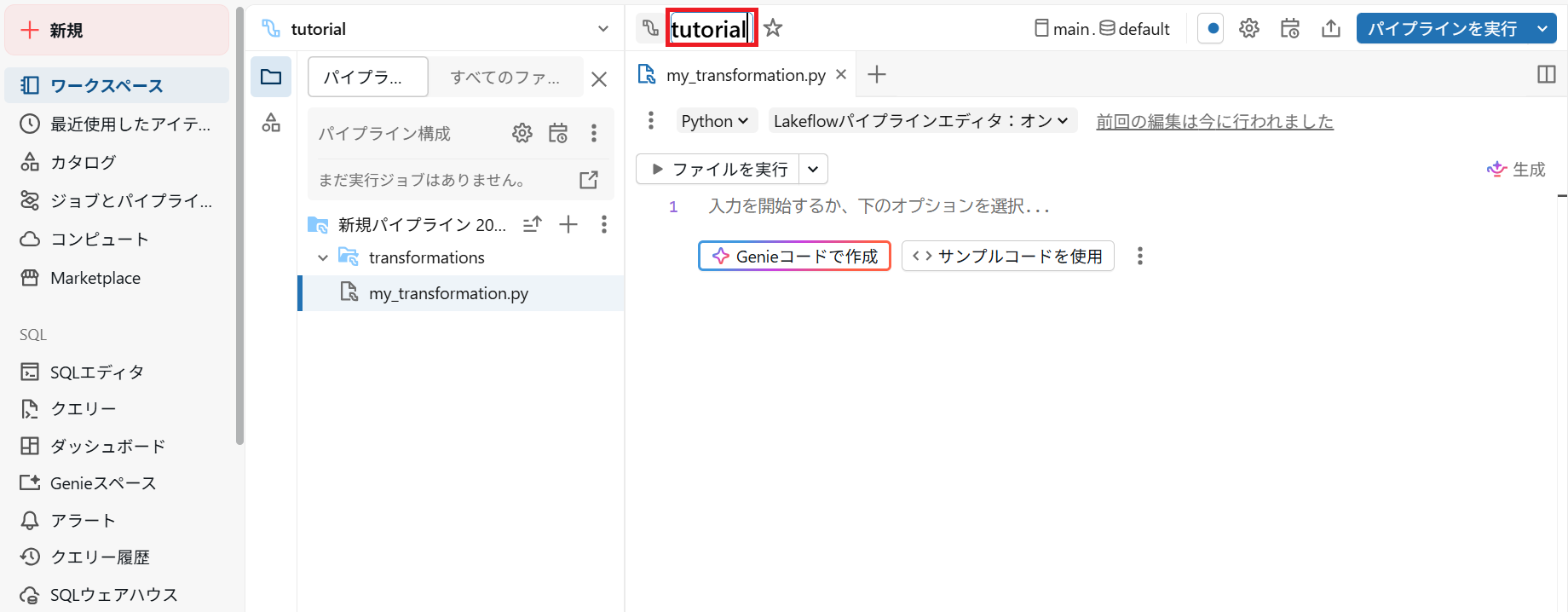
3.カタログとスキーマの設定
3.1.パイプライン名の右側にあるカタログとスキーマをクリック
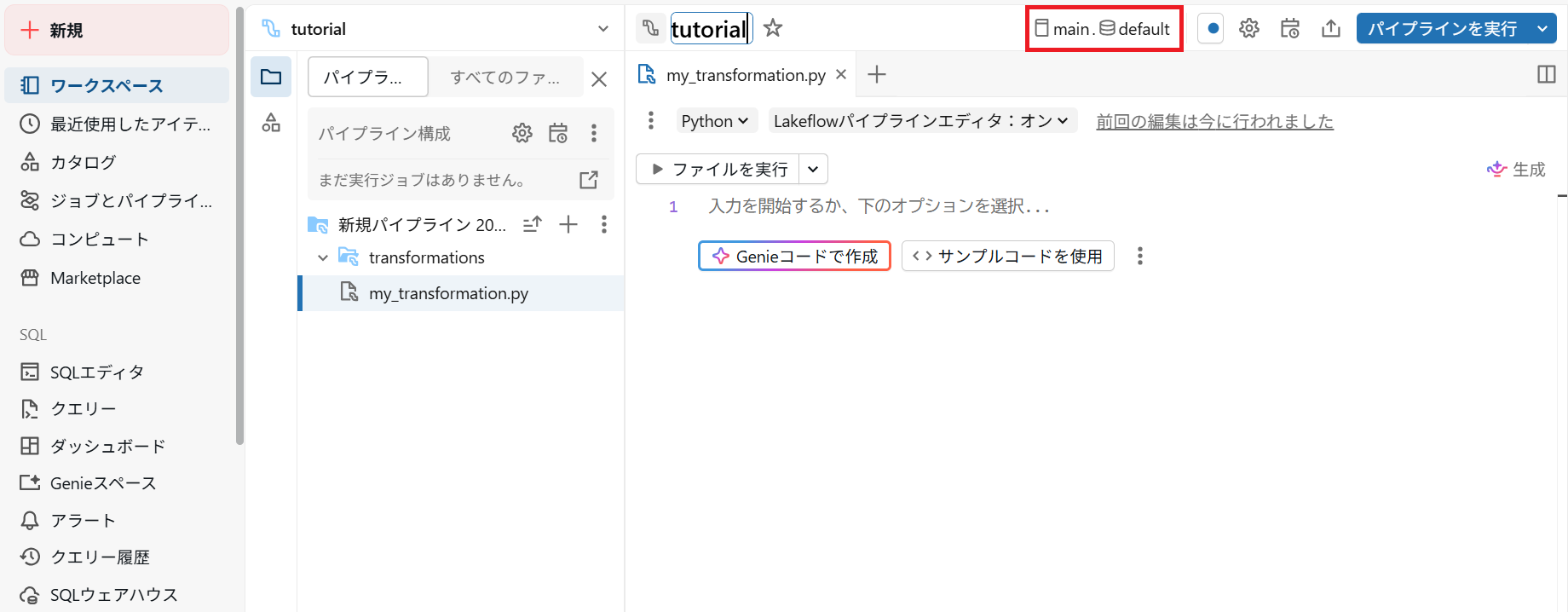
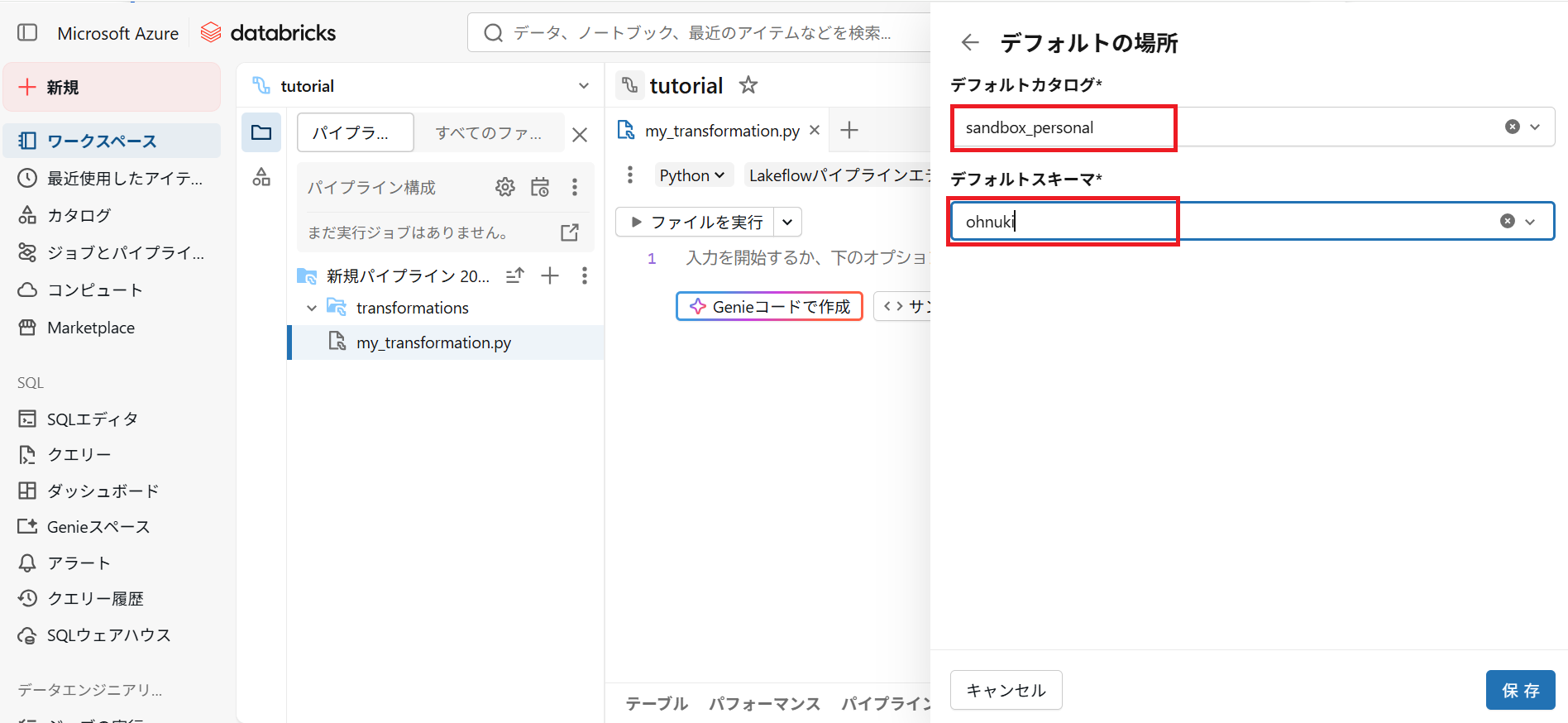
3.2.デフォルトで使用するカタログとスキーマを選択して保存
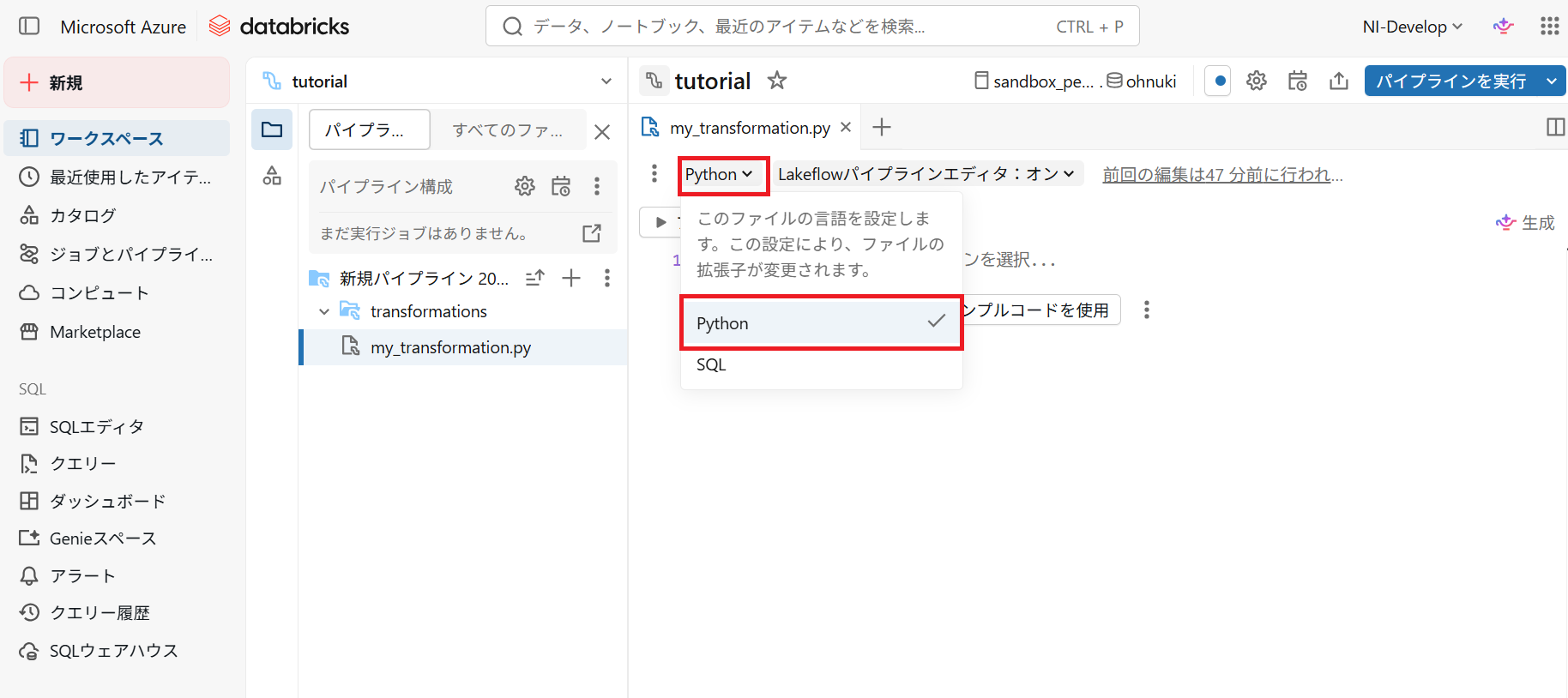
4.言語ドロップダウンリストから Python または SQL を選択
(今回はPythonを選択します)
5.「サンプルコードを使用」をクリック
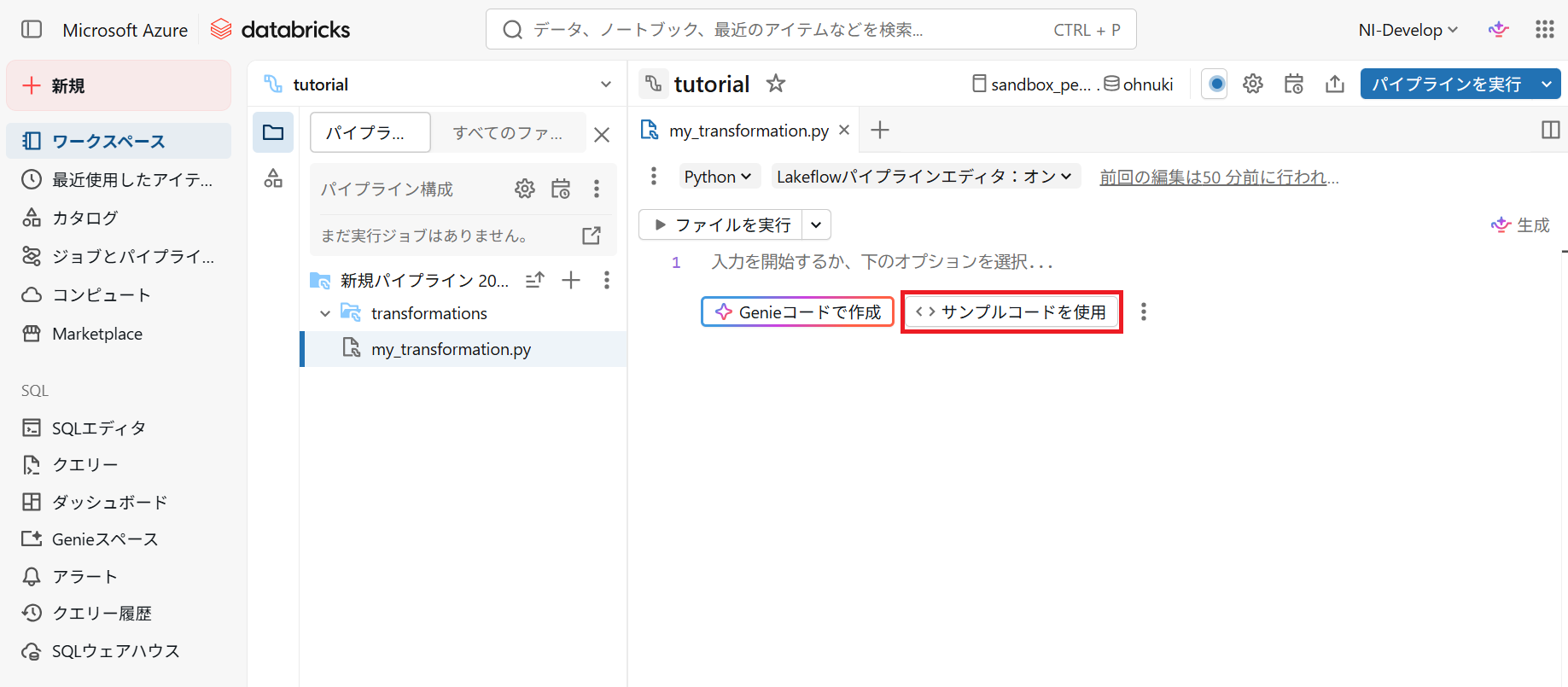
- pythonコードが2つと、utilitiesフォルダが追加されます
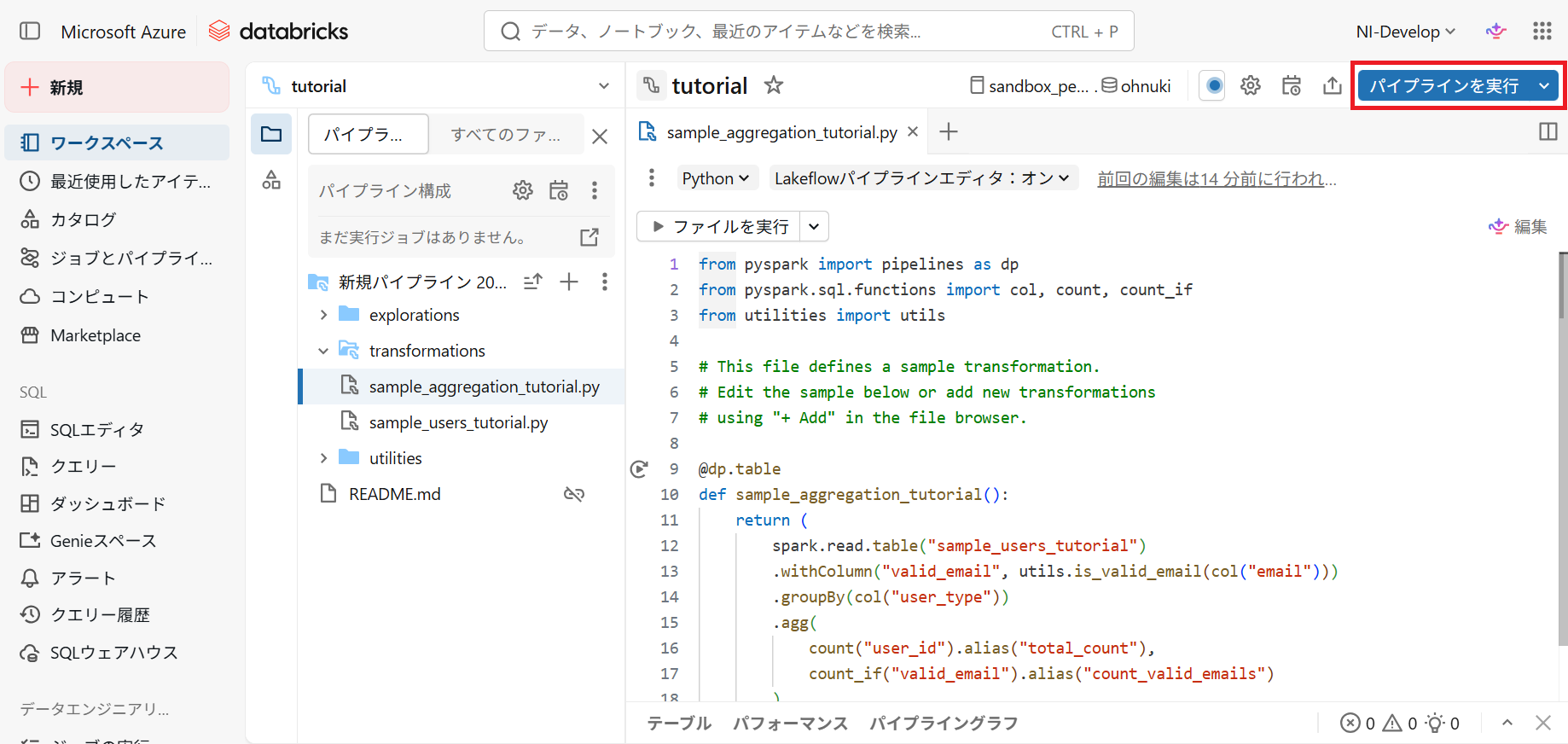
6.パイプラインの実行
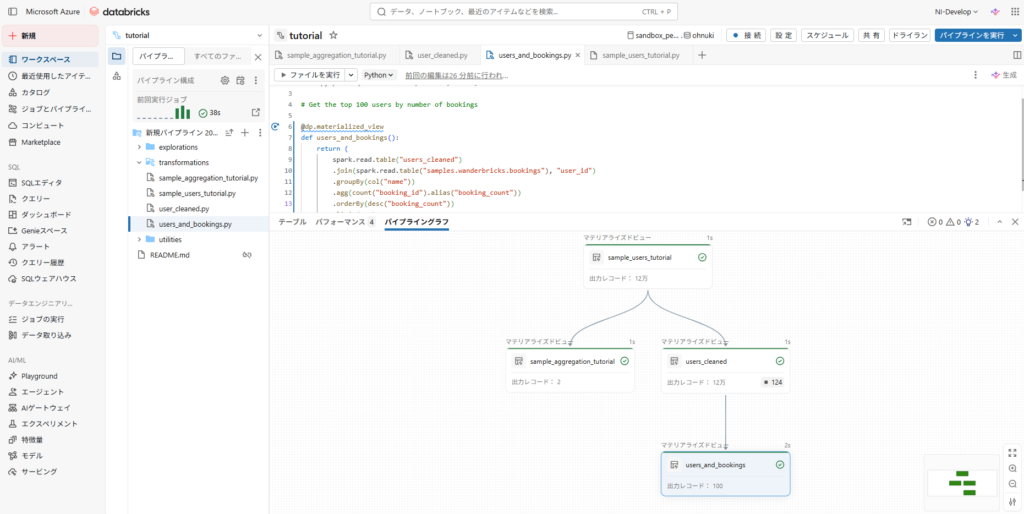
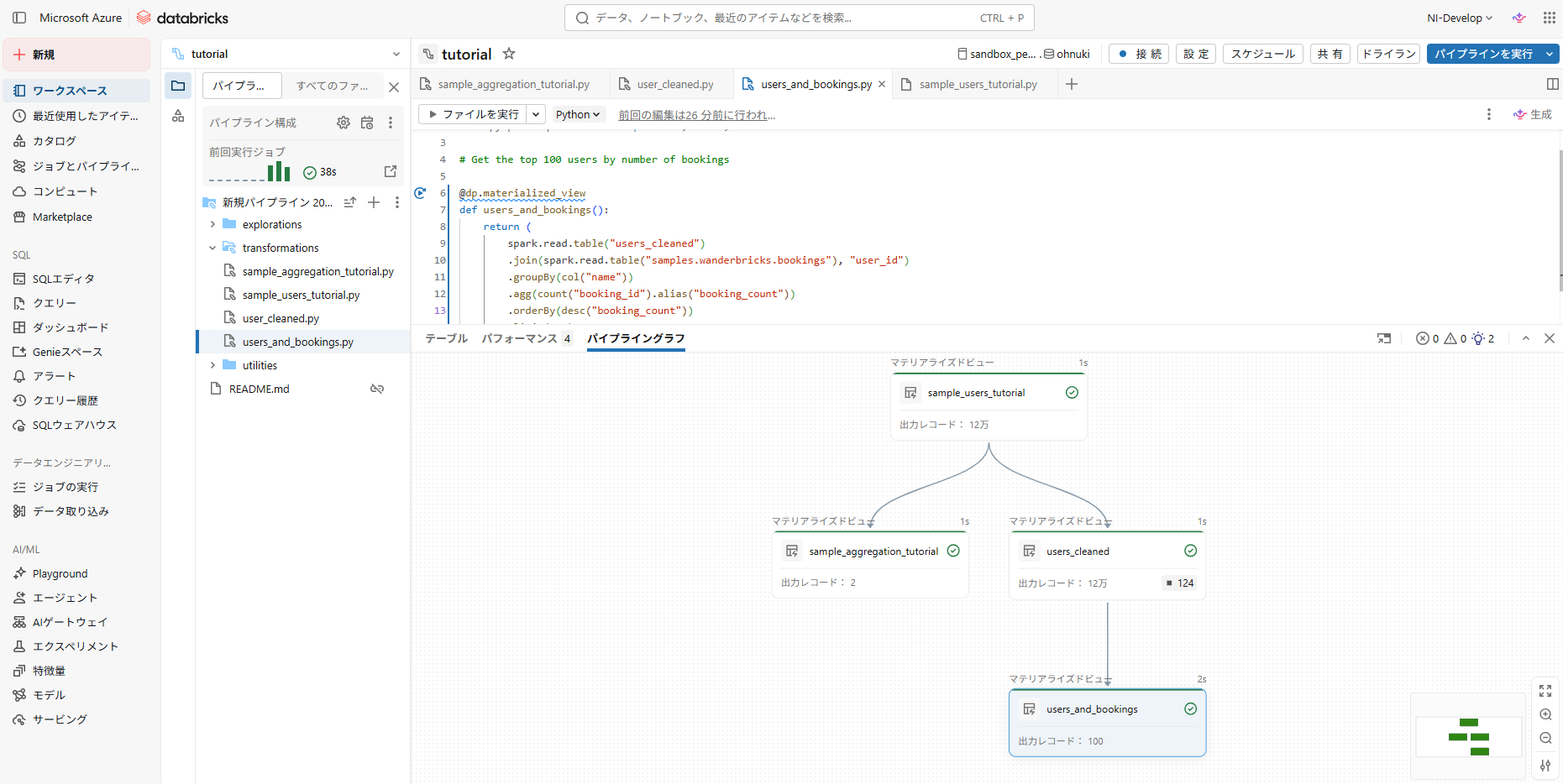
- 実行が完了すると、2つの新しいテーブルが表示されます(選択したカタログのスキーマに格納されています)
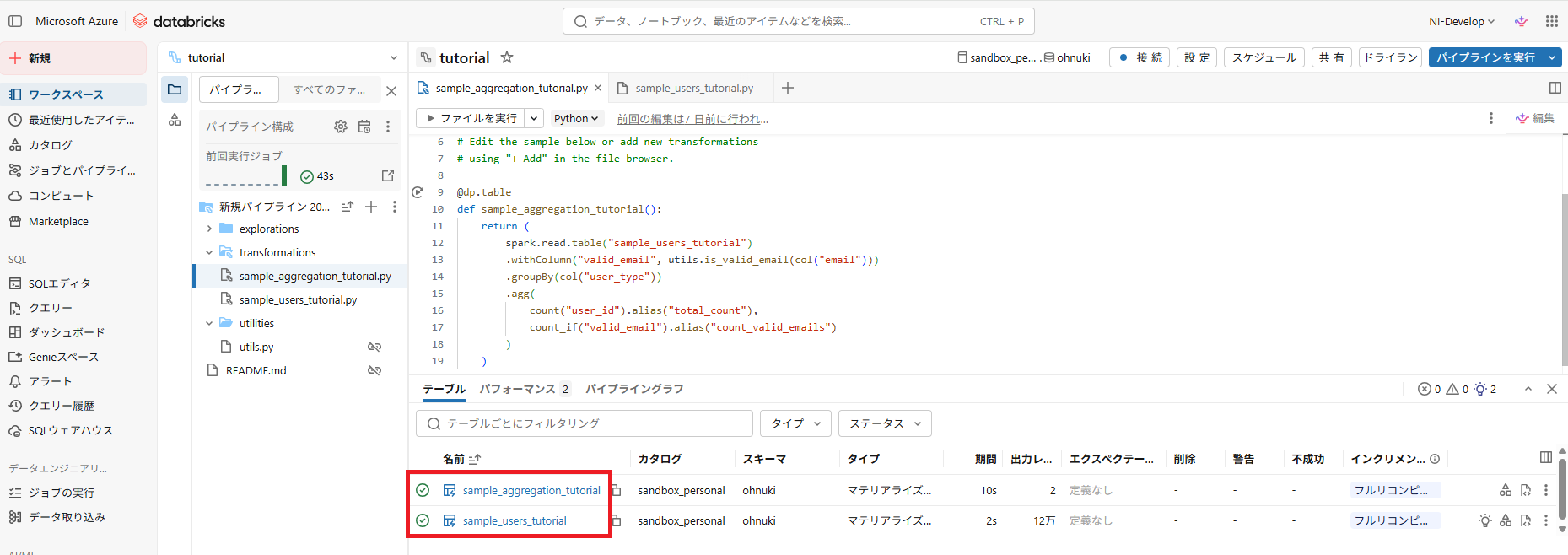
- パイプライングラフを見れば、テーブル間の依存関係を確認できます
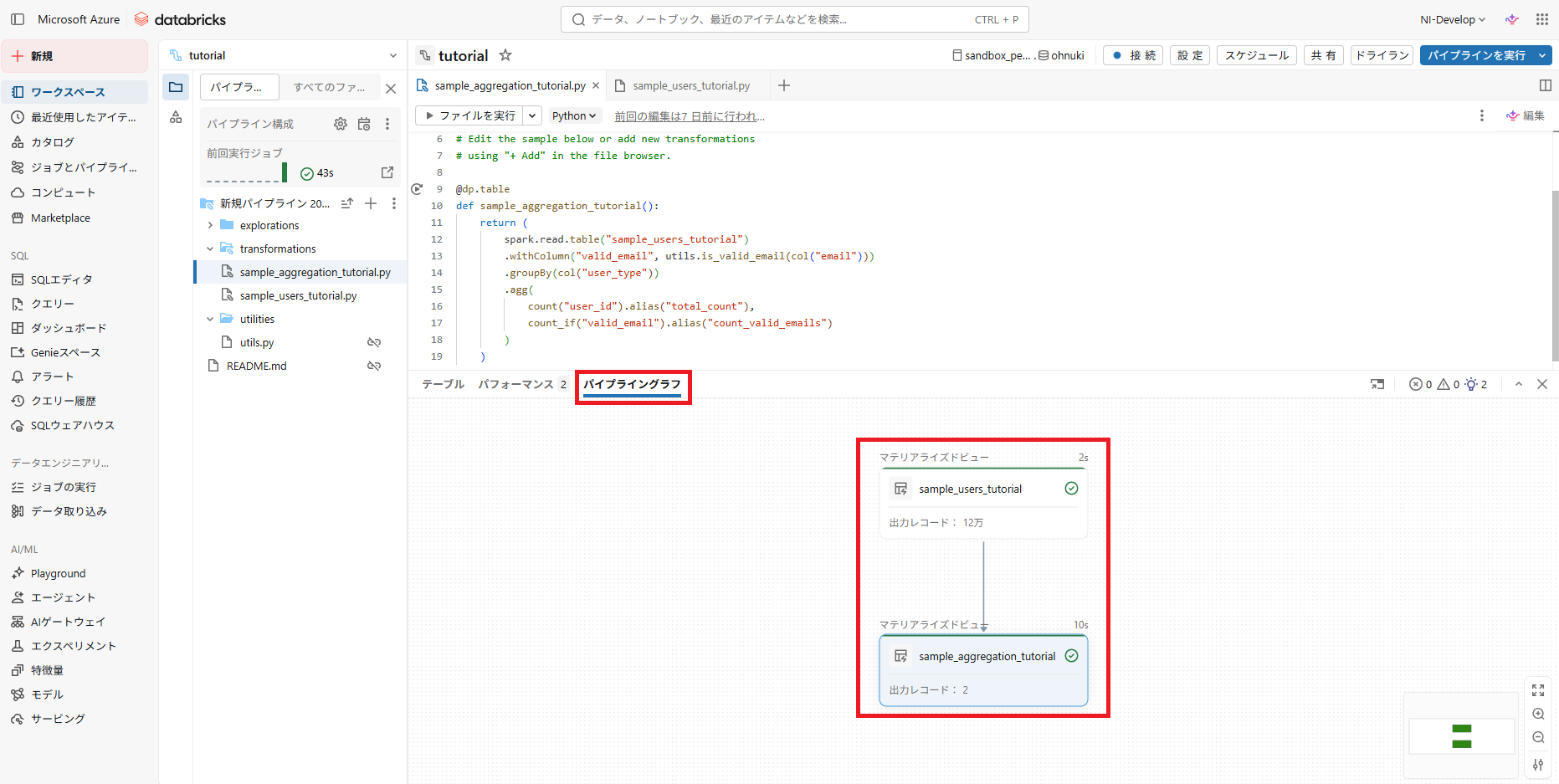
- コードについて
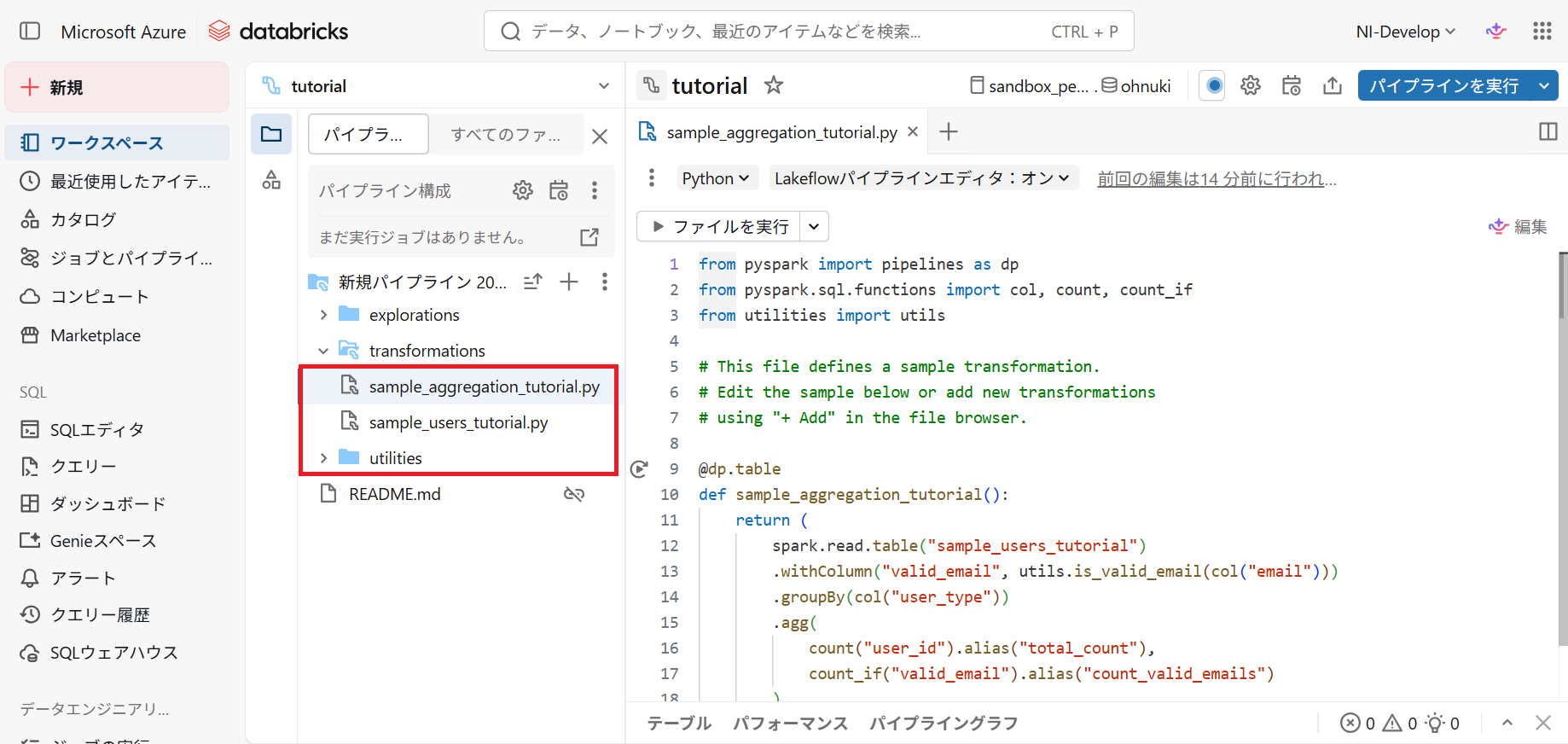
- sample_users_tutorial.py は samples.wanderbricks.users からカラムを抽出しています
- sample_aggregation_tutorial.py は sample_users_tutorialテーブル から valid_email カラムを作成し、user_type ごとに user_id と valid_email の数をカウントしています
手順2:データ品質チェックを適用する
1.「+」アイコンをクリックし、「変換」を選択
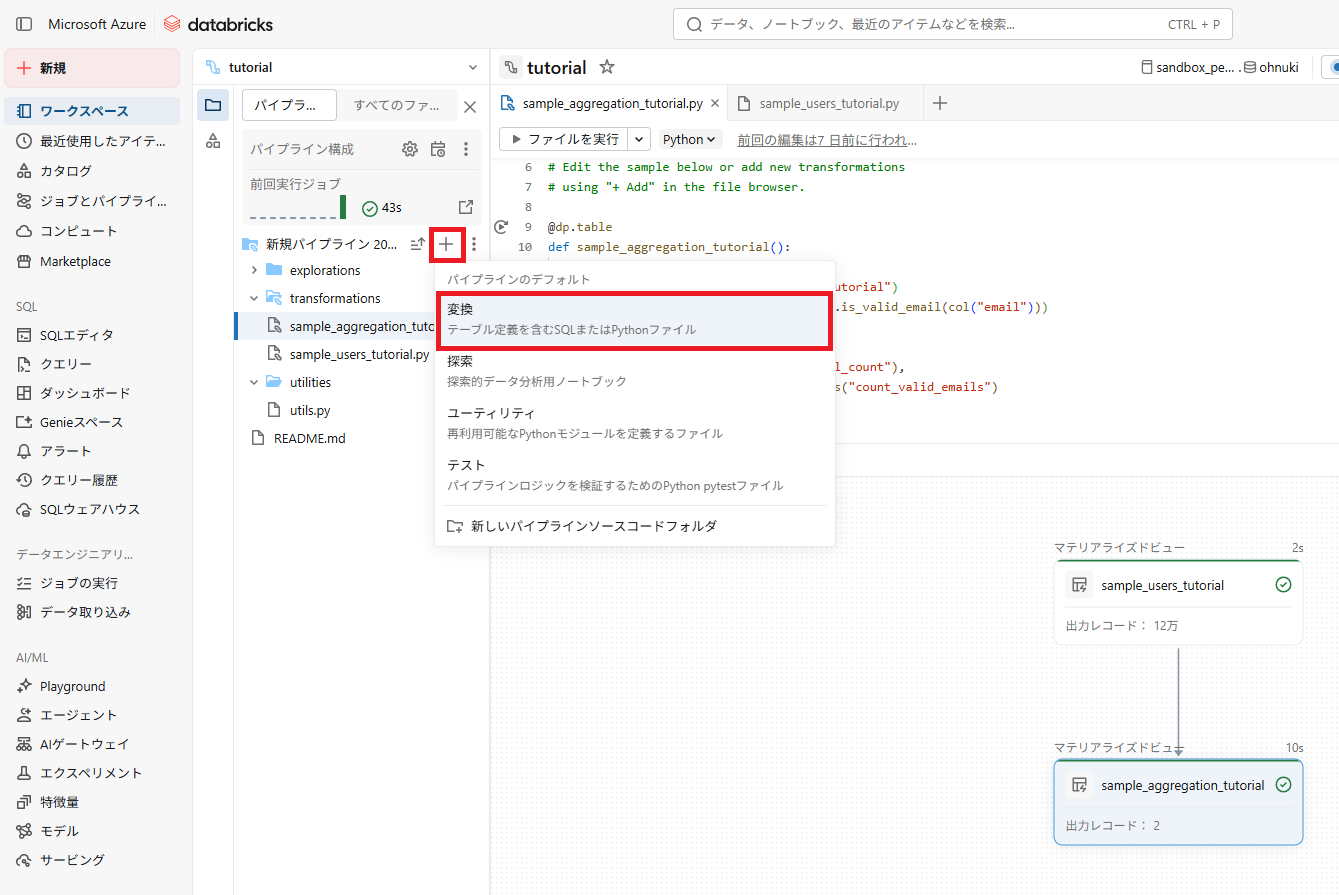
2.新しいコードの追加
2.1.Python または SQLを選択(今回はPythonを選択)
2.2.ファイル名を”users_cleaned.py”に変更
2.3.マテリアライズドビューをクリック(サンプルコードが生成される)
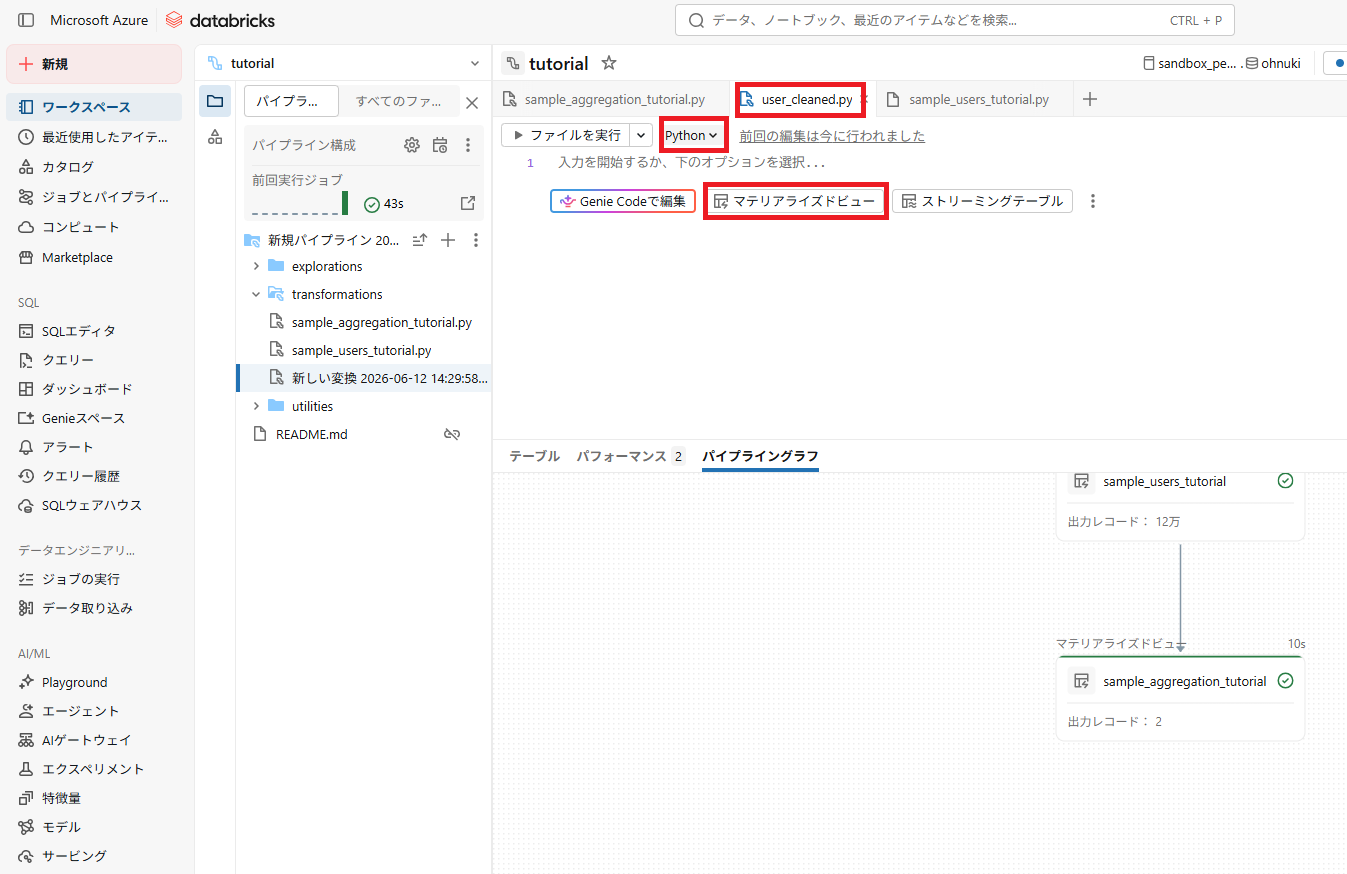
3.公式ドキュメントでは”[ 作成 ] をクリック”とありますが、2の時点でファイルが作成されます
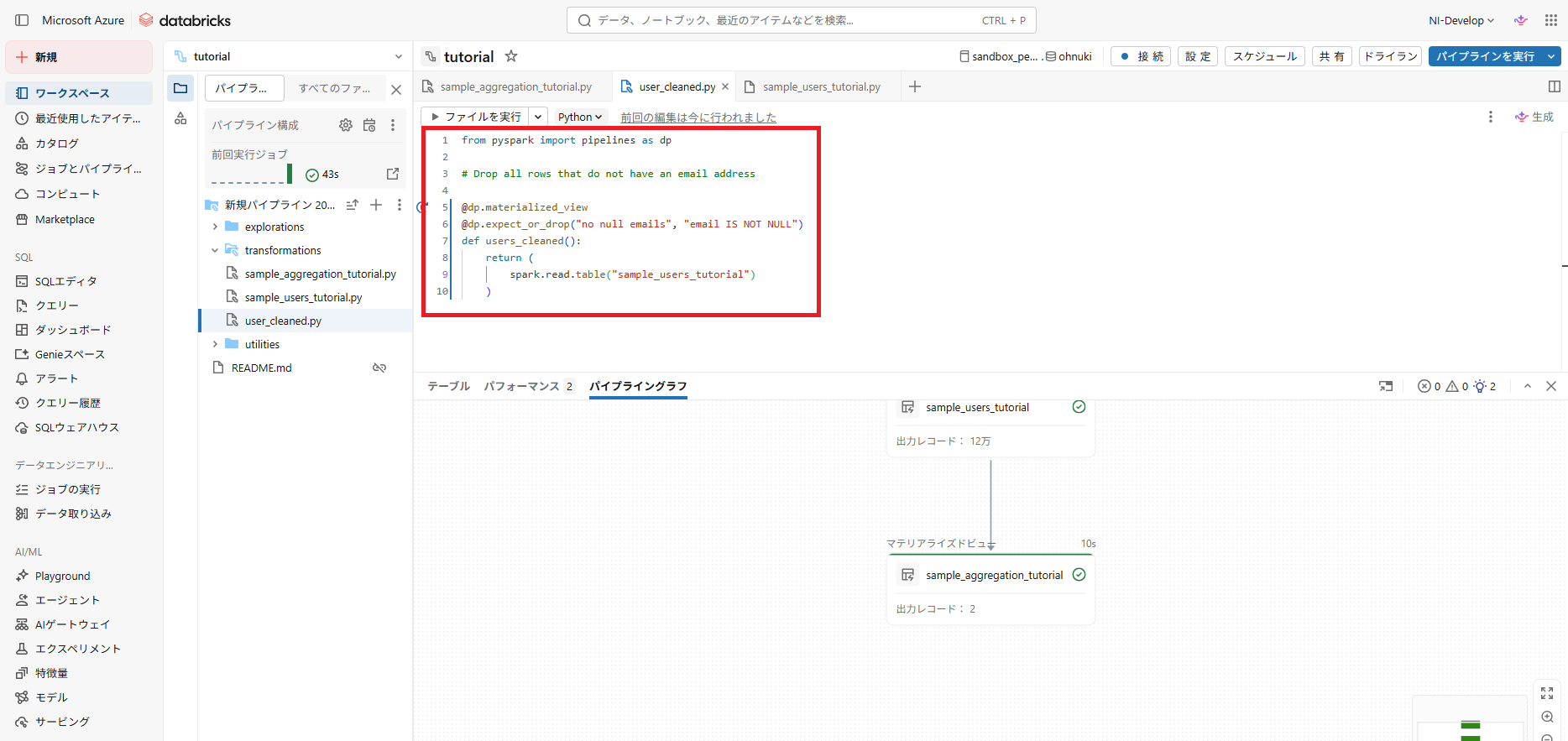
4.“users_cleaned.py”を下記の内容に編集(“sample_users_tutorial”は、実際のテーブル名に変更してください)
- @dp.expect_or_drop は、条件に違反したレコードを削除します。
今回の場合だと email が Null のレコードは削除されます。
drop の他に warn(警告だけで実行はされる) と fail(停止する) があります。
詳細はこちらをご覧ください。
from pyspark import pipelines as dp
# Drop all rows that do not have an email address
@dp.materialized_view
@dp.expect_or_drop("no null emails", "email IS NOT NULL")
def users_cleaned():
return (
spark.read.table("sample_users_tutorial")
)
5.パイプラインを実行、新しく”users_cleaned”テーブルができたことを確認
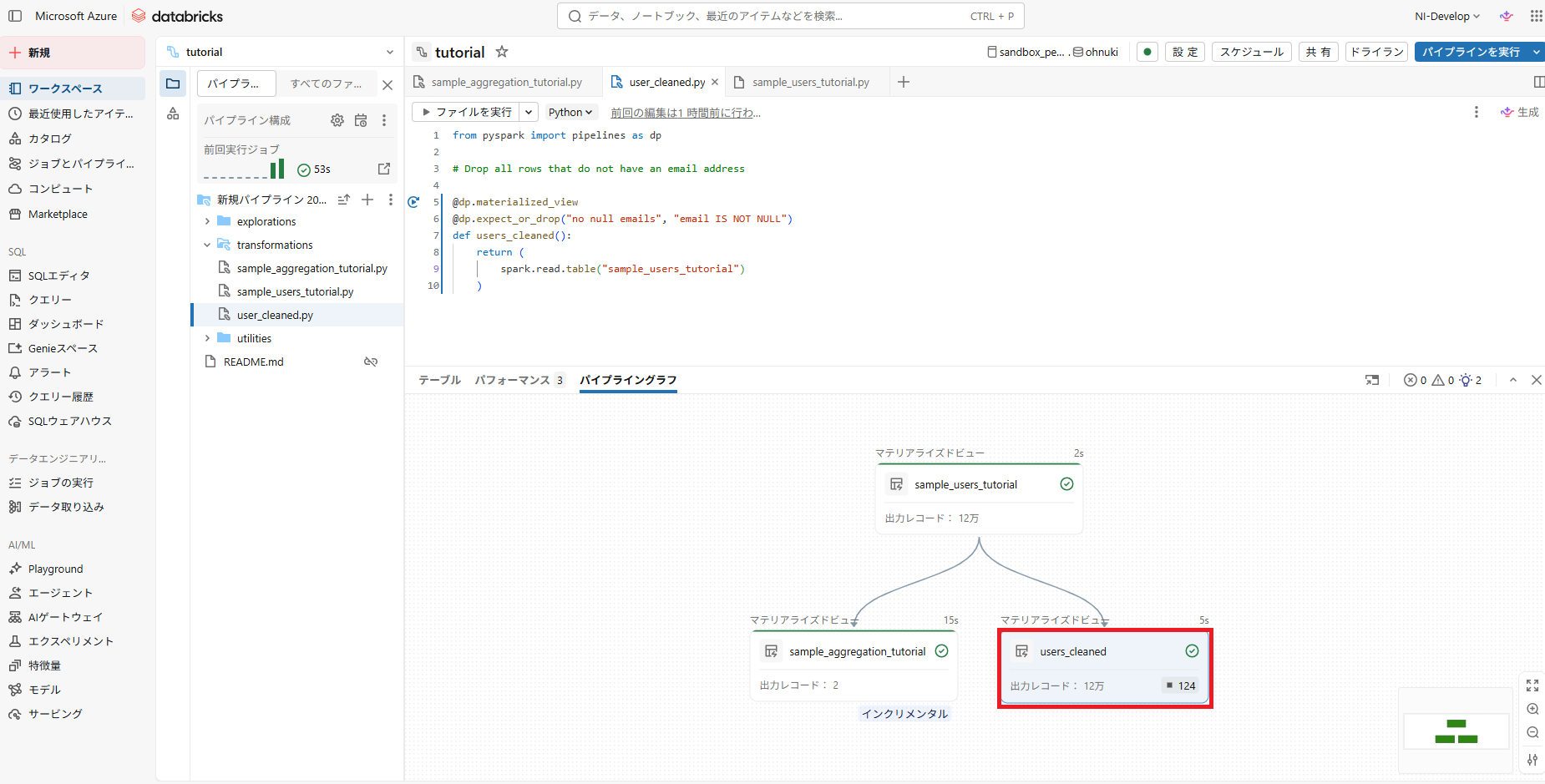
手順3:上位のユーザーを分析する
- 手順2とやることは同じなので、詳細は省略します
- 下記の内容で新しく「users_and_bookings.py」を作成し、パイプラインを実行します
from pyspark import pipelines as dp
from pyspark.sql.functions import col, count, desc
# Get the top 100 users by number of bookings
@dp.materialized_view
def users_and_bookings():
return (
spark.read.table("users_cleaned")
.join(spark.read.table("samples.wanderbricks.bookings"), "user_id")
.groupBy(col("name"))
.agg(count("booking_id").alias("booking_count"))
.orderBy(desc("booking_count"))
.limit(100)
)- 実行が完了すると、”users_and_bookings”テーブルができ、テーブルが4つになっていることが確認できます
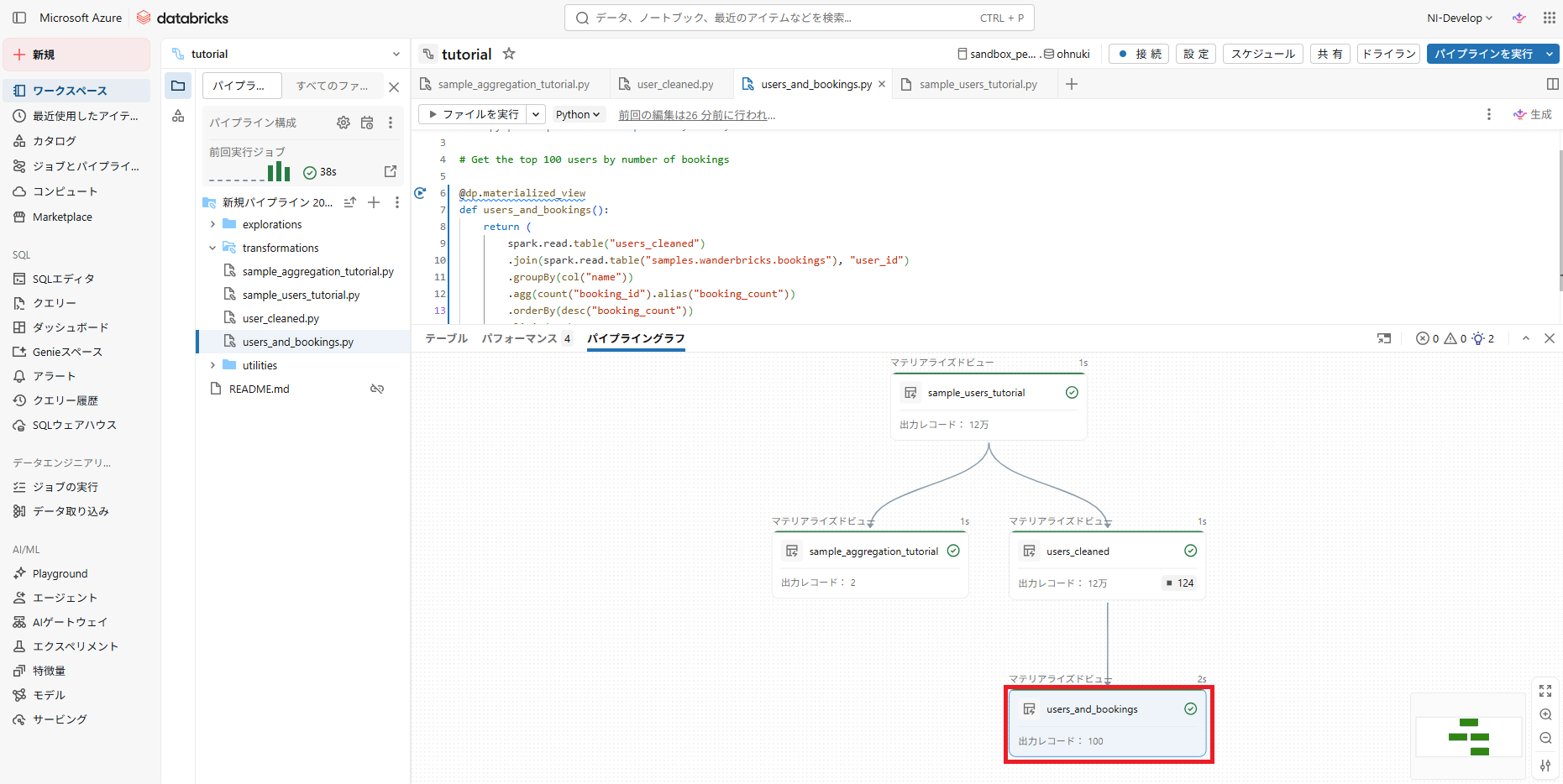
- 以上でチュートリアルは終了です
感想
- チュートリアルを動かしてみた感想です。
- 非常に簡単に実行でき、SDPがどういうものかよく分かるチュートリアルだと思いました。
- また、チュートリアルを元に、コードを少し変更したり、@dp.expect_or_dropの内容を変更してみたりすると、より理解が深まると思います。
- ただ、日本語の環境だと、デフォルトのパイプライン名が「新規パイプライン <date> <time>」になっています。
チュートリアルでは、テーブル名にパイプライン名が反映されるようになっているので、デフォルトのまま進めていくと、テーブル名に日本語が入ってしまいエラーになってしまいます。
そこだけ注意が必要かなと思います。
まとめ
- 本記事では、Lakeflow Spark 宣言型パイプラインについて紹介し、チュートリアルを動かしてみました。
作成したいテーブルを関数で定義するだけで、自動で依存関係を分析し、実行してくれることが視覚的にもお分かりいただけたと思います。
また、expect_or_drop などを使用することで、簡単にデータの制約を記述することができ、イレギュラーなデータが入ってきたときの対応ができることが分かりました。 - 今回のチュートリアルには続きがあります。
https://learn.microsoft.com/ja-jp/azure/databricks/ldp/tutorial-pipelines
こちらでは AUTO CDC を使用して、SCD タイプ2 の更新を行う方法などを紹介しています。
もしご興味のある方は是非試してみてください。 - 弊社ではDatabricksを活用したデータエンジニアリングや機械学習モデル構築など幅広くご支援させていただいております。データ活用でお困りのことがあれば、ご連絡いただけると幸いです。




コメント