






NI BLOG
ネイチャーインサイト株式会社の情報発信ブログ
SASに関する技術情報など





自然言語のクラスタリング【後編】実装の勘所
データアナリティクス部のAtakaです。
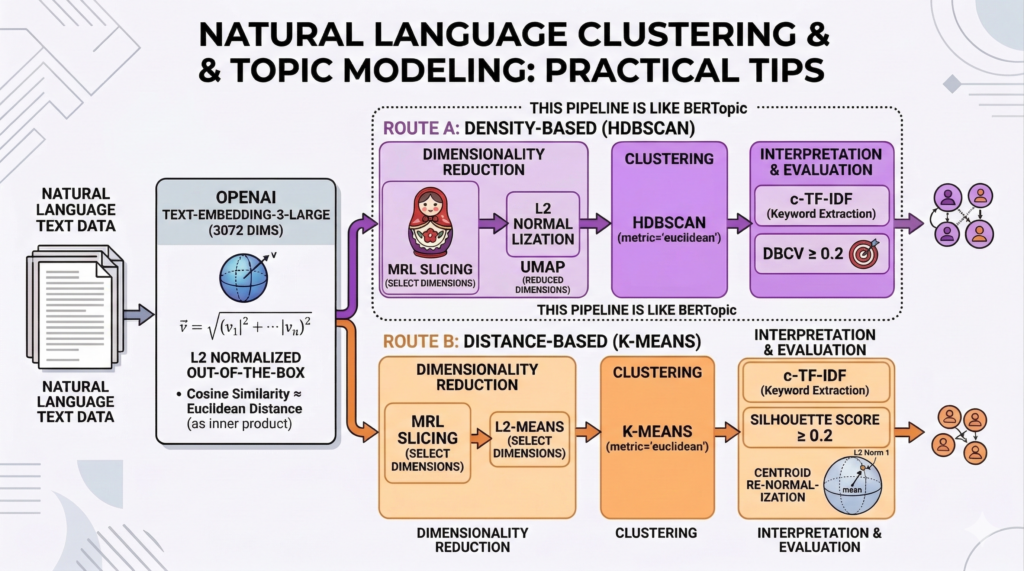
今回のブログ記事は、Gemini(Nano Banana2)にアイキャッチ画像を作ってもらいました。
細部をみると気になるところ(NORMAL-LIZATIONと”L”が被っているなど)もありますが、長くなってしまった記事の内容を上手に図にまとめてくれています。
さて、自然言語のクラスタリングについて、後編にあたる今回は、実装の勘所や実践的なTIPSを解説します。
具体的には、適切な次元削減方法の選択や、クラスタの解釈をどうするか、評価の相場感はどのくらいか、などの解説になります。
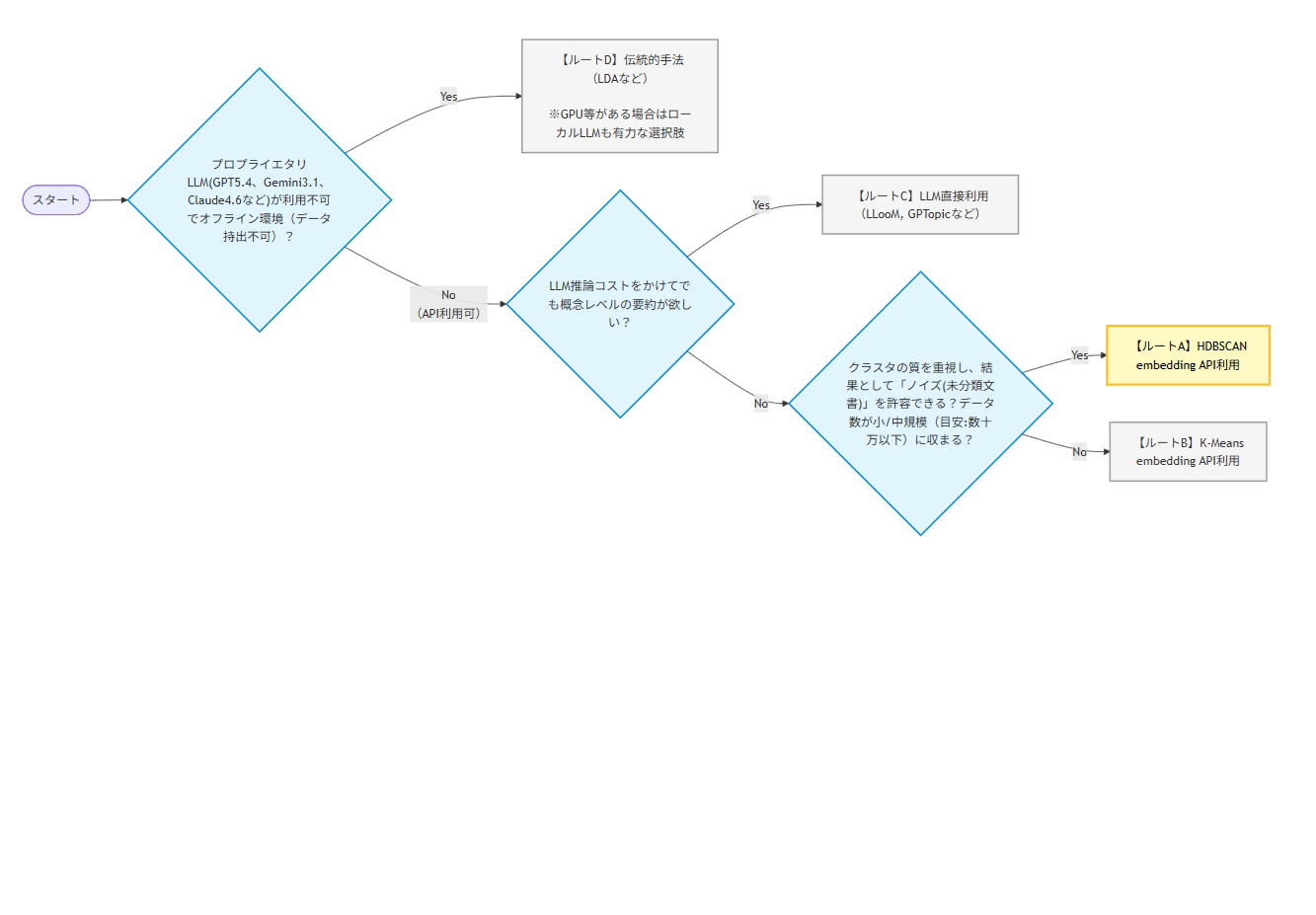
前編をまだ読んでない方は、あわせて以下の記事も目を通してもらえると嬉しいです!(が、後編だけでも独立して読めます)
OpenAI text-embedding-3 の使い方
今回のエンベディングには、OpenAI(やAzure OpenAI)の text-embedding-3-large を想定します。
この出力結果であるベクトルをクラスタリングに利用する上で、押さえておくべき基礎知識と実務上のTIPSを紹介します。
基礎知識:L2正規化
OpenAIのAPIから返ってくるベクトルは、すでにL2正規化された状態(単位球面上にある状態)になっています。公式ではベクトルの比較にコサイン類似度の利用が推奨されていますが、L2正規化済みであればコサイン類似度は「内積(ドット積:Dot Product)」の計算と一致します。実務上、これは大きなメリットです。内積はCPUやGPUを用いた行列演算の並列化が効きやすく、数百万件同士の類似度計算であっても高速に処理できるからです。
さらに、このL2正規化の恩恵により、コサイン類似度(内積)とユークリッド距離は実質的に近似して考えることができます。なぜなら、L2正規化された2つのベクトルuとv、(つまり ||u||=||v||=1)のユークリッド距離 dは、以下のように展開できるからです。
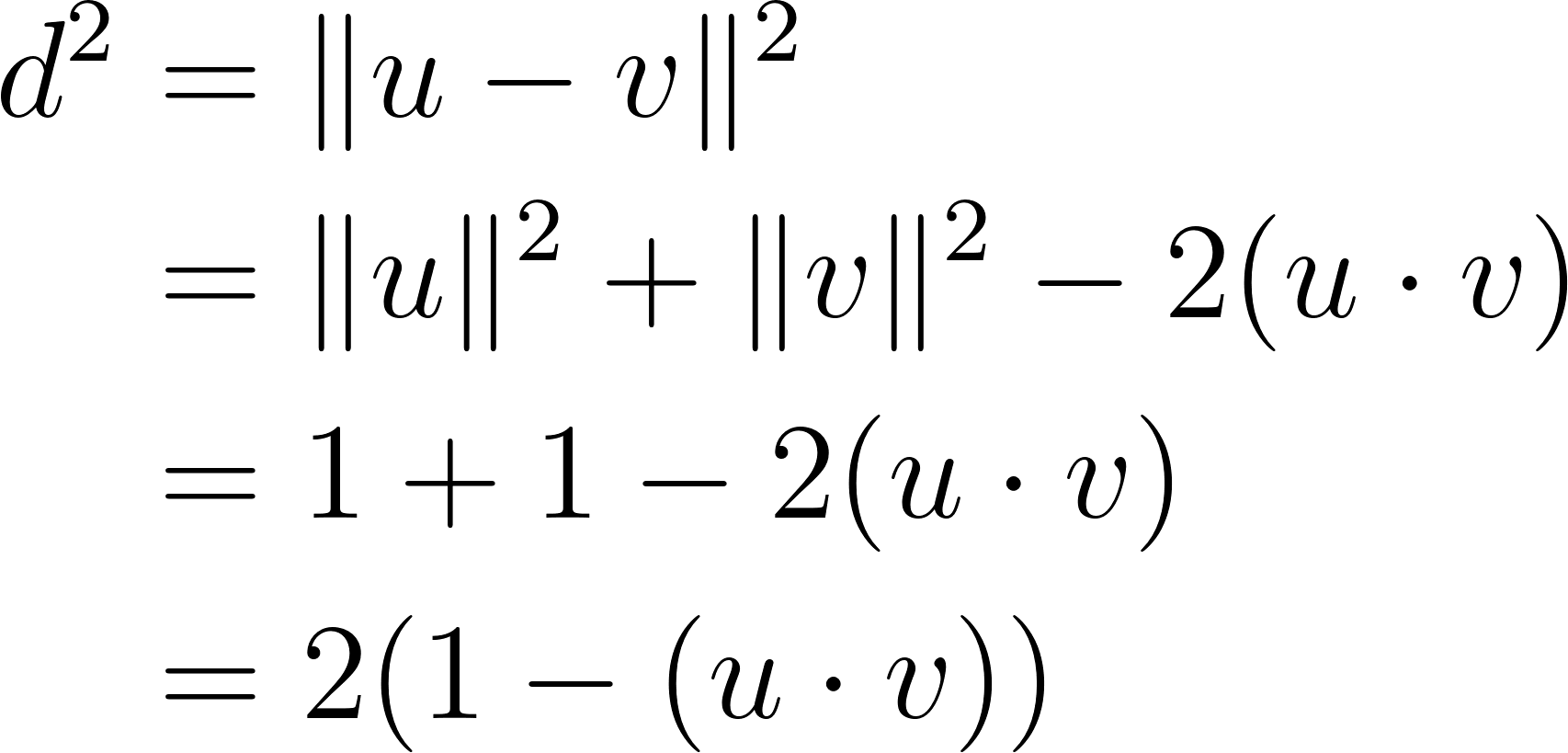
ユークリッド距離の2乗とコサイン距離(1-コサイン類似度のこと。正規化されているので1-内積)の2倍が等しくなる ことがわかります。二乗や定数倍の計算はデータ間の距離の「大小関係(順位)」には影響を与えません。(どのくらい遠い・近い、といったスケールは変わります。)
このため、クラスタリング手法(K-MeansやHDBSCAN)でユークリッド距離を用いたとしても、コサイン距離に近似する距離指標として、十分に機能するということがわかるかと思います。
※OpenAIのFAQでも以下のように言及しています。

※FAQの内容 超意訳
Q.どの距離関数を使うべきなの?
A.コサイン類似度を推奨するけど、ユークリッド距離と同じ順位になるから気にしなくてもいいよ。
基礎知識:MRL (Matryoshka Representation Learning)
text-embedding-3 の特徴として MRL で学習されている点が挙げられます。これは「重要な特徴量がベクトルの先頭次元に集まる」という性質を持っています。そのため、わざわざPCAのような複雑な計算を行わなくても3072次元のベクトルの先頭から任意の次元(例: 256次元や512次元)をスライスして取り出し、再度L2正規化を行うだけで、「次元削減された特徴量」としてクラスタリングに利用することができます。マトリョーシカのように、大きなサイズ(次元数)の中に、小さなサイズでも使える埋め込み表現が内包されている形ですね。
APIリクエスト時にdimensionsパラメータを指定して任意の次元数の埋め込み表現を取得することもできますが、手元でも削減は容易なので、リクエスト時は圧縮する前の生?の高次元のベクトルを取得しておくのがおすすめです。
※OpenAIのUseCaseでも以下のサンプルコード(embedding結果をスライスしL2正規化する手順での次元削減のコード)が載せられています。
from openai import OpenAI
import numpy as np
client = OpenAI()
def normalize_l2(x):
x = np.array(x)
if x.ndim == 1:
norm = np.linalg.norm(x)
if norm == 0:
return x
return x / norm
else:
norm = np.linalg.norm(x, 2, axis=1, keepdims=True)
return np.where(norm == 0, x, x / norm)
response = client.embeddings.create(
model="text-embedding-3-small", input="Testing 123", encoding_format="float"
)
cut_dim = response.data[0].embedding[:256]
norm_dim = normalize_l2(cut_dim)
print(norm_dim)実務TIPS:コスト半額のBatch API
クラスタリング対象となるテキストデータは、数万〜数百万件に及ぶことも珍しくありません。
APIを利用して大量のテキストをエンベディングする場合、同期的な応答が不要(基本的に分析実施時点では不要なことが多い)であれば、通常の同期処理のエンドポイント(v1/embeddings)でなく、 Batch APIのエンドポイント(v1/batch)の利用を推奨します。24時間以内に結果が返ってくる非同期処理※になる代わりに、APIの利用コストを約半分(50%オフ) に抑えることができます。
※24時間以内という仕様ですが、実務経験上、リクエストの処理はサーバーサイドで並列化して処理されるため、通常のembedding APIを逐次実行で叩く場合よりも早く処理が終わることが多い体感です。
次元削減とクラスタリング手法の組み合わせ
次元削減とクラスタリング手法には相性がありますので、以下で推奨の組み合わせを紹介します。
HDBSCANの場合(前編 でのルートA)
HDBSCANのような密度ベースのクラスタリングを行う場合、次元削減には PCA よりも UMAP の方が相性が良いです。
UMAPは「近傍に集まっている点をより近づけ、離れている点はより離す」という非線形な次元圧縮を行うため、密度ベースでクラスタを識別するHDBSCANにとって有利な次元圧縮方法といえます。
推奨パイプラインは以下の通りです。
- text-embedding-3-large から先頭次元をスライス
- スライスしたベクトルを L2正規化
- UMAPで次元圧縮(密度の濃淡を強調)
- HDBSCANに入力し、ユークリッド距離でクラスタリング
以下、実装イメージです。
import numpy as np
from sklearn.preprocessing import normalize
from umap import UMAP
from hdbscan import HDBSCAN
# 1000×3072次元ベクトル(1000文書のOpenAIダミーベクトル)
openai_embeddings = np.random.rand(1000, 3072)
# スライスして512次元に
mrl_cut_embeddings = openai_embeddings[:, :512]
# L2正規化
mrl_l2_embeddings = normalize(mrl_cut_embeddings,norm="l2")
# UMAPで50次元に
umap_model = UMAP(n_neighbors=3, n_components=50, metric='cosine', random_state=42)
umap_embeddings = umap_model.fit_transform(mrl_l2_embeddings)
# そのままHDBSCANに投入、ユークリッド距離で計算
hdb_model = HDBSCAN(
min_cluster_size=3,
metric='euclidean',
cluster_selection_method='leaf',
prediction_data=True
).fit(umap_embeddings)
# クラスタラベルの取得
labels = hdb_model.labels_UMAPの前にスライス(MRL)を挟む意味は?
「UMAP単体でも次元削減できるのになぜ事前にスライスするのか?」と疑問に思うかもしれません。これには2つの理由があります。
- 計算コストの削減: 3072次元のままと比べると、事前に数百次元に落とすことで処理が高速化します。
- 構造の抽出: 後方の微細な次元を事前にカットしておくことで、UMAPがより大局的な話題のまとまりを捉えやすくなります。
ユークリッド距離を使うのにクラスタリング前(UMAP後)にL2正規化しなくてよいの?
HDBSCANの前処理では、UMAPの出力に対してL2正規化を行わないほうがよいです。UMAPはデータ間の距離や密度の濃淡を低次元空間にマッピングしますが、ここでL2正規化をしてしまうと全データが原点からの距離が1の「球面上」に再配置され、せっかくUMAPが抽出した密度の違いを壊してしまいます。
密度の違いを活かすためにも、UMAPの出力はそのままHDBSCANに渡すほうが理にかなっています。
K-Meansの場合(前編 でのルートB)
全データを必ずどこかのクラスタに割り当てるK-Meansの場合、推奨の次元削減方法はMRLでスライスし、L2正規化する、になります。
HDBSCANで使用したUMAPのような非線形次元圧縮は、K-Meansが前提とする大域的な距離関係を破壊してしまうため、K-Meansの前処理としては推奨されません。PCAだと線形圧縮で次元削減できるので、K-Meansの前処理として検討する方が多いですが、PCAの「情報量の多い順に次元を並べ直す」という役割をMRLがより高度に果たしているため、重ねてPCAを行う必要はないかと思います。
推奨パイプラインは以下の通りです。
- text-embedding-3-large から先頭次元をスライス
- スライスしたベクトルを L2正規化
- K-meansに入力し、ユークリッド距離でクラスタリング
- クラスタの重心を再度L2正規化して利用
以下、実装イメージです。
import numpy as np
from sklearn.cluster import KMeans
from sklearn.preprocessing import normalize
# 1000×3072次元ベクトル(1000文書のOpenAIダミーベクトル)
openai_embeddings = np.random.rand(1000, 3072)
# スライスして256次元に
mrl_cut_embeddings = openai_embeddings[:, :256]
# L2正規化
mrl_l2_embeddings = normalize(mrl_cut_embeddings,norm="l2")
# そのまま通常のK-meansに投入
kmeans = KMeans(
n_clusters=10, # 任意のクラスタ数を指定
random_state=42,
n_init='auto'
)
# クラスタラベルの取得
labels = kmeans.fit_predict(mrl_l2_embeddings)
# 重心をL2正規化(球面上に引き戻す)
spherical_centroids = normalize(kmeans.cluster_centers_, norm='l2', axis=1)コサイン類似度を使うK-Meansで実装したほうがよいのでは?
厳密にいうと、ユークリッド距離ベースのK-Meansよりも、コサイン類似度を直接扱う Spherical K-Means(球面K-Means) の方が理論的には向いているかと思います。ただ、Spherical K-Meansはデータ分析でよく使われるscikit-learnには実装がありませんし、前述の通り今回扱うベクトルはL2正規化されているため、通常の(球面でない)K-Meansでも実用上は十分に近似した分類が可能です。そのため、実務では通常のK-Meansが用いられることが多いです。
重心を再度L2正規化する意味は?
通常の(球面でない)K-Meansを使用する場合、「クラスタの重心(Centroid)」は、クラスタに所属する点の算術平均になっています。球面上に存在する点の平均をとると、その計算結果である重心ベクトルは球面の内側に窪んでしまい、L2ノルムが1以下に短くなってしまいます。
後続の処理でこの重心ベクトルを再利用する(例:新しい文書と重心の類似度を計算する)こともあるので、計算された重心ベクトルを再度L2正規化して、単位球面上に戻す処理を挟むようにしてください。そうすることで「内積 = コサイン類似度」という前提を維持することができます。
仮に正規化せずに重心ベクトルの長さが0.8に縮んでしまっているままで、新しい文書(長さ1)と内積で類似度計算をしてしまうと、計算結果は(角度が全く同じ向きでも)1.0 × 0.8 = 0.8 で重心ベクトルの長さが最大値になってしまいます。各クラスタの重心からの類似度を測るときに重心の長さに引っ張られてスケールが変わってしまっては困りますね。ベクトルの扱いを揃えておくほうがバグを産みにくいですし、内積計算のほうが(コサイン類似度の計算よりも)早いため、正規化して他のベクトルと同様に扱えるようにしておきましょう。
閑話:なぜ球面上の平均は「内側」に落ち込むのか?
ここは個人的に面白いと感じるポイントなので、本題とは逸れますが、閑話として少し解説を加えておきます。
K-Meansの重心計算のように「球面上の点(長さが1のベクトル)の平均」をとると、なぜ長さが1以下になるのでしょうか。
数学的なロジックとしては、すべての点が同じ値でない場合は「二乗の平均」と「平均の二乗」は一致しない(平均の二乗の方が小さくなる)という、イェンセンの不等式が関係しています。
例えば、1辺2cmの正方形と1辺4cmの正方形があるとして、面積(二乗)の平均を計算すると、 (4 + 16) / 2 = 10 です。しかし、辺の長さの平均 (2 + 4) / 2 = 3を出してから面積(二乗)を計算すると 9 にしかなりません。ベクトルのL2ノルム(長さ)は各要素の二乗和の平方根であるため、計算の順序が入れ替わる重心(平均)ベクトルは、元の長さ(1)を維持できず短くなってしまうのです。
直感的なイメージとしては「時計の文字盤(円)」を思い浮かべてください。12時の位置と4時の位置のちょうど「中間」は、文字盤の2時の位置(円周部)ではなく、内側に窪んだ位置にあります。
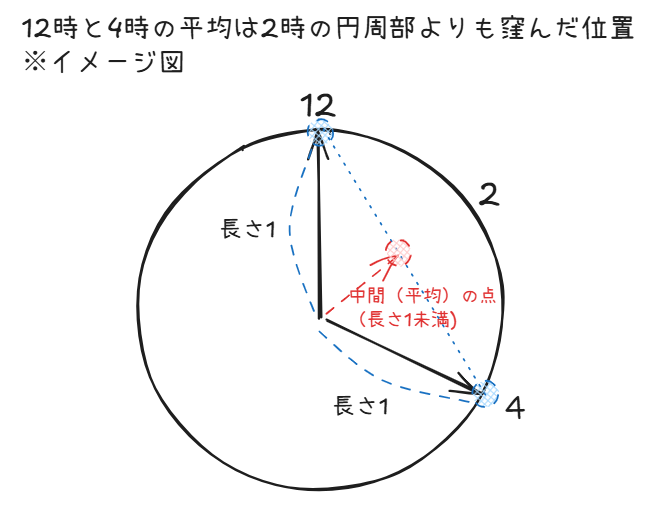
時計の文字盤は2次元の円での例ですが、高次元の球面でも同じことが起きるんだよ、と考えるとイメージしやすいかと思います。
クラスタ(トピック)をどう解釈するか?
クラスタリング結果が出たら、「そのクラスタがどんな話題なのか」を解釈するステップが必要になります。
ここで活躍するのが、 c-TF-IDF (Class-based TF-IDF) です。通常の TF-IDF は1文書、つまり、1件のデータの単位で単語の重要度を計算しますが、c-TF-IDF は「クラスタ(トピック)単位」を1文書と見なして TF-IDF を計算します。これにより、そのクラスタを特徴づけるキーワードを抽出できます。
実務TIPS:c-TF-IDFのメモリ消費
数万〜数十万件の文書を基に c-TF-IDF を計算しようとすると、語彙数が膨大になり、計算の過程で生成されるスパース行列が巨大になりすぎてメモリがクラッシュすることがあります。これを防ぐためには、TF-IDFを計算する前の段階で、低頻度単語を足切りするなどの 前処理を入れておく、といった対策が必要になります。
クラスタリング結果の精度をどう評価するか?
クラスタリング結果の良し悪しを定量的に評価する指標として、代表的なものは以下になります。
密度か距離かは違いますが、どちらも似たような発想の評価指標になります。詳細は割愛します。
- HDBSCAN(密度ベース)の場合: DBCV (Density-Based Clustering Validation)
- K-Means(距離ベース)の場合: シルエットスコア (Silhouette Score)
実務TIPS:スコアはどのくらいあればよいの?
スコアがどれくらいあれば十分と言えるのかを考える上で重要なのが、自然言語のエンベディング空間の特性です。文脈を捉えた自然言語のベクトルは密度が高く、通常のテーブルデータのクラスタリングのように綺麗にクラスタが分かれることは稀です。様々な話題が連続的に、まるで雲がかかるように混じり合って分布しています。
これは感覚値となりますが、自然言語のクラスタリングにおいて、DBCV や シルエットスコアが「0.2以上」であれば、1つの合格点(十分に意味のある分割ができている) と見なして良いのではないでしょうか。
もし「0.4」を超えるようなスコアが出ているわかれ方をしていたら、別ジャンルの話題が混入しているような(話題が明確に分けられる)データセットだった、と言えるレベルではないかと思います。
実装の勘所まとめ
後編では、OpenAIのエンベディング結果を駆使したクラスタリング実装の勘所を解説しました。まとめです。
- 次元削減: 次元の呪いを解くためにMRLスライスを活用。K-Meansはスライスと正規化のみ、HDBSCANはスライスと正規化、UMAPを組み合わせる。UMAP後の正規化はNG。
- 数理的理解: L2正規化による内積計算のメリットと、球面上の平均の特性(イェンセンの不等式)を理解しておく。
- 解釈と評価: c-TF-IDFでキーワードを抽出し、スコア0.2を合格点の目安とする。
トピックモデリングは面白い
今回紹介したクラスタリングのパイプラインの1つ、embedding->UMAP->HDBSCAN->c-TF-IDF、という流れですが、これは実は、BERTopicと呼ばれるトピックモデリング手法と同じものです。

※出典:https://maartengr.github.io/BERTopic/algorithm/algorithm.html
機械学習の文脈でよく使われる「クラスタリング」という用語に囚われず、自然言語処理の「トピックモデリング」という領域に目を広げてリサーチすると、自然言語からどのように話題を抽出するか?という課題に対する様々な先人の知恵を発見(例えばこのBERTopicや、前編で挙げたLLooM、GPTopicといったLLMベースの手法などを発見)できます。
トピックモデリングもLLMの発展に合わせて手法が進化していて面白いので、興味を持ったら調べてみてください!
弊社では自然言語処理やLLM活用、機械学習モデル構築など幅広くご支援させていただいております。
データ活用でお困りのことがあれば、お問い合わせいただけると幸いです。




コメント