






NI BLOG
ネイチャーインサイト株式会社の情報発信ブログ
SASに関する技術情報など





自然言語のクラスタリング【前編】手法選択
データアナリティクス部のAtakaです。自然言語処理関連の分析やLLM活用関連を頑張っています。
テキストデータを分類し、そこにどんな話題が含まれているか把握したい、というのは、実務でもよく遭遇する状況の1つです。
しかし、「LDAなどの昔ながらの手法で十分か?」「次元削減手法として、UMAPやPCAは挟むべきか?」「いっそLLMに全部任せてしまえばいいのでは?」など、適用する手法を選択するだけでも、考えることが結構たくさんあります。
本記事では、『【前編】手法選択』 として、実務における自然言語のクラスタリングにおける手法選択のフローチャートと、それぞれの手法のPros/Consを整理します。
手法選択フローチャート
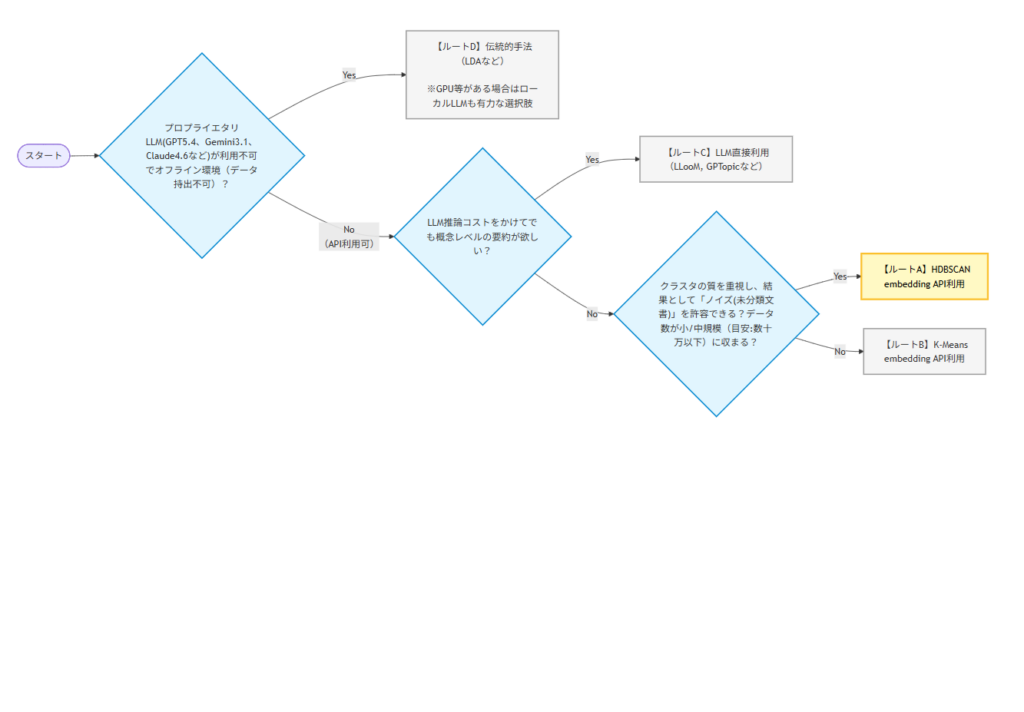
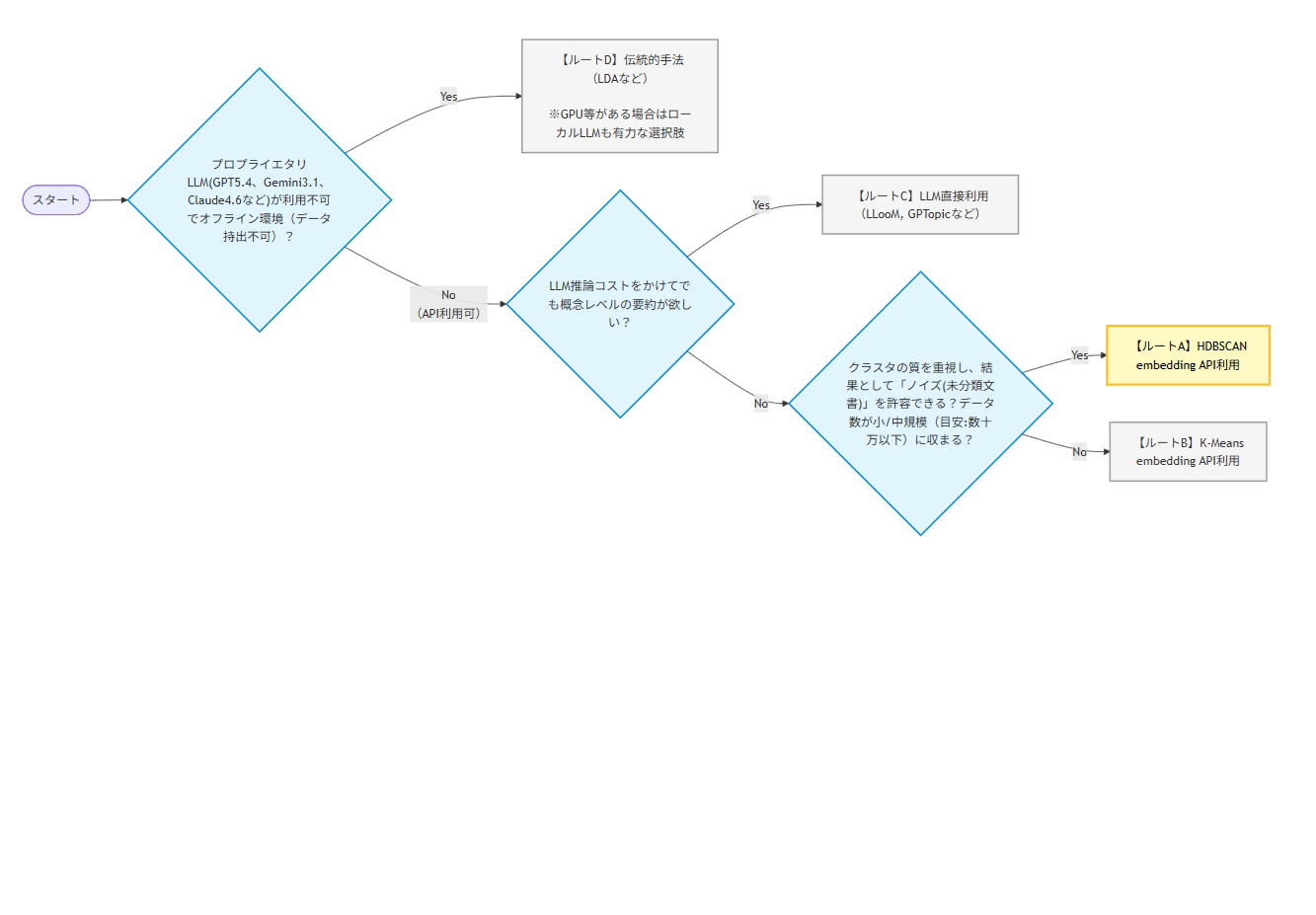
今回の結論をフローチャートにまとめました。以下の図をみてください。
フローチャートで色を塗ってある【ルートA】が今の王道になる手法かと思います。

以下はフローチャートの文字起こしです。
- Q1.プロプライエタリLLM(GPT5.4、Gemini3.1、Claude4.6など)が利用不可でオフライン環境(データ持出不可)?
- Yes ➔ 【ルートD】伝統的手法(LDAなど)
- No(API利用可) ➔ Q2へ
- Q2. LLM推論コストをかけてでも、概念レベルの要約が欲しい?
- Yes ➔ 【ルートC】LLM直接利用(GPTopic、LLooMなど)
- No ➔ Q3へ
- Q3. クラスタの質を重視し、結果として「ノイズ(未分類文書)」を許容できる?データ数が小/中規模(目安:数十万以下)に収まる?
- Yes ➔ 【ルートA】HDBSCAN
- No ➔ 【ルートB】K-Means
テキストデータ分析、自然言語クラスタリングにおいて、2026年現在、コストパフォーマンスと精度のバランスに優れているのは、OpenAIなどのプロプライエタリなLLMのembedding APIを用いた「ルートA(HDBSCAN)」と「ルートB(K-Means)」になるかな、と思います。
この2つの手法、HDBSCANとK-Meansについて、少し掘り下げます。
話題の「抽出」には HDBSCAN
特定のクラスタにおいて、「話題のコア」をしっかり抽出したい場合は、密度ベースのクラスタリング手法である HDBSCAN が有力です。HDBSCANの最大のメリットは、密度の低い領域にあるデータを「ノイズ(未分類)」として扱えることです。無理に全てのデータを分類しないため、純度の高いクラスタを得ることができます。
指定個数への「分割」には K-Means……で本当によいの?
一方で、「この文書は必ずK個のカテゴリに分けたいんだ」という明確な要件がある場合は、距離ベースの K-Meansが選択肢となります。
ですが、自然言語の複雑な分布をK-Meansで無理やり分割すると、人間が1つのトピックだと解釈できる単位にクラスタがまとまっていない(ノイズが混在する)という問題がけっこう起きがちです。
そのため、「未分類をなくしたい」「全件を必ず分類したい」という要件であっても、K-Meansを採用するのではなく、「まずは HDBSCAN で純度の高いクラスタのコアを作り、その後、近しいクラスタを統合したり、ノイズと判定されたデータはk-NNなどで近いクラスタに割り当てる(ノイズを減らす)」 という2段構えのアプローチをとる方が、結果的に意味のある分類になることが多いです。
となると、K-Meansを選択するメリットって何?となりそうですが、データ規模の観点ではK-MeansがHDBSCANより有利です。
HDBSCANや(その前処理としてよく使われるUMAP※は)データ数が数十万〜数百万件を超えると計算量が爆発し、メモリ不足などで破綻しやすくなります。なので、数百万件以上の大規模データを高速に処理したい場合は、計算速度に優れるK-Meansが現実的な選択肢として復活します。
※HDBSCANの推奨前処理は後編記事で触れます。お楽しみに
各手法の Pros / Cons
以下、その他のルートも含めた比較表です。
| ルート名 | 主な手法 | Pros(メリット) | Cons(デメリット) | 推奨ユースケース |
|---|---|---|---|---|
| ルートA | HDBSCAN (embedding API利用) |
トピックの純度が高い。意味のあるまとまりを作りやすい。 | 文書数が数十万件を超えると厳しい。 | FAQの自動抽出など (実務全般で使える手法) |
| ルートB | K-Means (embedding API利用) |
計算が高速で大規模データにもスケールする。必ず全データが指定したK個に分類される。 | 無理やり指定個数に分割するためノイズが混在しやすい。 クラスタの解釈が難しい。 |
数百万件のログ分類など |
| ルートC | LLM直接利用 ※LLooM, GPTopicなど (Responses API利用) |
トピックの解釈を単語の羅列ではなく、概念レベルで要約できる。 | LLM推論コストと処理時間が膨大になる。 | 予算が潤沢で、数百〜数千件の定性データを納得感高く分類したいとき |
| ルートD | LDA (Latent Dirichlet Allocation) |
完全オフライン動作。1文書が複数トピックに属する確率を出せる。 | 文脈や同義語を理解できない。短いテキスト(SNS等)は精度が出にくい。前処理が大変。 | APIやGPUが使えない環境で長文文書(論文、ニュース等)を分類したいとき |
その他のルート:ローカルLLM
完全オフライン環境の選択肢としてフローチャートでは伝統的手法のLDA(ルートD)を挙げましたが、もし手元にGPUなどの計算資源がある場合は、オープンなエンベディングモデル(E5、BGEなど) や ローカルLLM(Qwen、GPT‑OSSなど) をオンプレミスで動かすアプローチも選択肢となります。
API利用コストや情報漏洩リスクを抑えたうえで、ルートA・B・Cと同じ手法で「意味・文脈を捉えたトピック抽出」を実現できるため、セキュリティ要件の厳しい環境ではこの構成も選択肢に挙がるかと思います。
手法選択まとめ
データ分析の手法全般そうですが、自然言語のクラスタリングにも「これを選べば正解!」といえる銀の弾丸はありません。
重要なのは、以下の観点から手法を選ぶことかと思います。
- 環境: 完全オフライン必須なら伝統的手法(LDAなど)、計算資源があるならローカルLLM/SLM
- 求めるレベルと予算のバランス: コストと時間をかけてでも概念レベルで要約したクラスタを抽出したいならLLMで直接推論
- 精度と規模のバランス: それ以外の実務の大部分は、高精度のHDBSCAN、または大規模向けのK-Means
そして実装へ
実務的にはルートAやBがコストと精度のバランスが良さそうだな、と手法選択を済ませたとします。
では実装、と進み、例えば、OpenAIのtext-embedding-3-large を叩くと、 3072次元 という高次元のベクトルが返ってきます。
これをそのままクラスタリングアルゴリズムに突っ込むと、計算量が爆発するだけでなく、データ間の距離の差が薄れてしまい、上手く分類できなくなってしまう「次元の呪い」にかかります。
この高次元特有の課題にどう対処し、精度を出すか?という点でも、色々と考慮しなけれならない点があります……が、記事が長くなってしまったので、この先は【後編】実装の勘所 に譲り、本日は筆を置きたいと思います。
弊社では自然言語処理やLLM活用、機械学習モデル構築など幅広くご支援させていただいております。
データ活用でお困りのことがあれば、お問い合わせいただけると幸いです。
※追記:後編も公開しました。あわせて目を通してもらえると嬉しいです!



コメント