






NI BLOG
ネイチャーインサイト株式会社の情報発信ブログ
SASに関する技術情報など





SIGNATEのデータ分析コンペで入賞しました(金メダル)
初めまして、日頃の業務でもデータ分析を担当していますt.iijimaと申します。
少し投稿が遅くなりましたが、この度2022/4/13~6/2に開催された下記のSIGNATEのデータ分析コンペにて、
4位入賞(Private LB :6位(金メダル) / 835人投稿)いたしました。
ソニーグループ合同 データ分析コンペティション(for Recruiting)大気中の汚染物質濃度の予測に挑戦しよう!
https://signate.jp/competitions/624
この記事では、今回入賞に至った解法をご紹介することを主な目的として、以下の内容にについて記載いたします。
■コンペの問題設定
■実施した解法
■結果の推移
■考察など
■コンペの問題設定
今回のコンペの目的は、世界各地の都市の大気観測データや気象情報を用いて、
特定の日付×都市の「PM2.5濃度」を予測することです。
●データの内容
学習・テストデータについての内容は以下のようになっています。
データの粒度:日付×都市
目的変数:PM2.5濃度(1日の中央値)
説明変数:
・年月日、国名、都市名、緯度、経度
・大気物質濃度(CO,O3,SO2,NO2)、気象情報(気温、湿度、気圧、風速、露点温度)
↑それぞれの大気物質濃度・気象情報の1日の観測回数、最小値、中央値、最大値、分散
※外部データを条件付きで使用することも可能ですが、この解法では使用していません。
データについての留意点:
・学習データとテストデータでそれぞれ異なる都市が含まれています。(都市の数:学習:239、テスト:63)
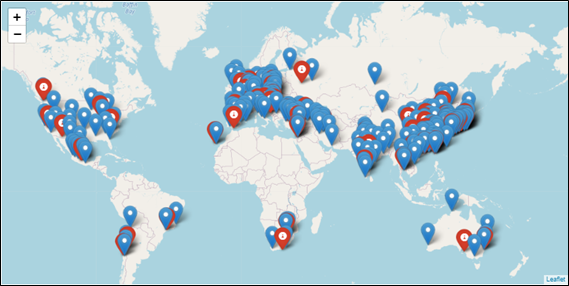
PM2.5が既知の学習データの都市とPM2.5が未観測のテストデータの都市のマップは以下になります。
マップ 学習データの都市:青いピン、テストデータの都市:赤いピン

※Pythonのfoliumライブラリの機能を使用して作成
→世界各地の都市が含まれていますが、都市が少ない地域も存在しています。
・データ期間:2019/01/01~2021/12/31(3年間)
→学習データとテストデータで同じ期間であるため、未来のPM2.5を予測する課題ではなく、
PM2.5が観測されている都市のデータから未観測の都市のPM2.5の値を補完する課題になっています。
ただし都市ごとに日付が存在しない(レコードがない)場合があります。
●評価指標:RMSE
評価指標はRMSEで、小さいほど良い指標となります。

RMSEは残差(=実績値-予測値)の絶対値が2乗で反映されるため、予測値を大幅に外すとRMSEが極端に大きくなる傾向があります。また、一般に実績値が大きいほど予測値を外す幅が大きくなる傾向があるので、大きい値を正確に予測することがよりRMSEの改善につながります。例えば、PM2.5の実績値が30のレコードを0と予測してしまうことは稀ですが、実績値が400のレコードを370と予測してしまうことは起こりやすいので、予測値が外れやすい大きな値をより正確に当てるほうがRMSEを改善しやすいと考えられます。今回の解法の場合、PM2.5が大きいと予想される都市や時季でより正確に予測することがRMSEの改善につながりました。
■実施した解法
今回実施した解法として、以下の4つの内容を順にご説明します。
①特徴量エンジニアリング
②データ加工
③モデリング
④テストデータの予測値の補正
①特徴量エンジニアリング
空間的・時間的な類似性を捉えるための特徴量を全6種類8つ作成しました。
●空間的な類似性を捉えるための特徴量
「距離が近い都市のPM2.5濃度は似ているだろう」という仮説を反映する特徴量を作成しました。
1. エリア
距離が近い都市をグルーピングして、36個のエリアのカテゴリ変数を作成
エリアのイメージ

→距離的な近さをより正確に捉えるために国名に替えるものとしてエリアを作成しました。
(国名で距離的な近さを捉えにくい例として、アメリカ合衆国では距離の遠い東海岸と西海岸の都市を含んでいることや、ヨーロッパでは距離的に近い場所に多くの国が存在していることがあります。)
※今回は緯度経度に基づいて手動で閾値を決めて作成しましたが、k-means法でクラスタリングすることが一般的かと思います。
2. 近くの都市のPM2.5
1,2番目に距離が近い学習データの都市の同日のPM2.5を作成
→距離が近い都市のPM2.5濃度は似ているだろうという仮説を直接反映する特徴量になります。
3. エリアごとのPM2.5の平均値
日付×(1.で作成した)エリアごとのPM2.5の平均値を作成
→こちらも距離が近い都市のPM2.5濃度は似ているだろうという仮説を反映する特徴量になります。
1,2番目に距離が近い都市のPM2.5よりも広域での近くの都市のPM2.5を反映しています。
※学習データの説明変数を作成する場合は、リークしないようにするため、当該レコードを除いて平均しています。
●時間的な類似性を捉えるための特徴量
「近い日付のPM2.5濃度は似ているだろう」という仮説を反映する特徴量を作成しました。
4. 日付
既存の説明変数の年・月・日から間隔尺度の日付の変数を作成
→日付の大小関係と間隔を正確に反映します。
5. エリアごとのPM2.5の平均値の1日前、1日後の値
(3.で作成した)日付×エリアごとのPM2.5の平均値の1日前、1日後の値を作成
→近い日付のPM2.5濃度は似ているだろうという仮説を反映する特徴量になります。
※都市ごとの1日前、1日後のPM2.5を説明変数に入れないのは、テストデータの都市において1日前、1日後のPM2.5が得られないためです。
6. 1日前の風速
同じ都市の1日前の風速[中央値]を作成
→1日前の風が大きくPM2.5が飛ばされたり、逆に風が小さくPM2.5が留まったりすることが反映されると考えられます。
◆変数重要度一覧
上記の特徴量を含めて作成したLightGBMでの変数重要度の上位は以下のようになりました。
エリアの重要度が特に大きくなっていて、都市の距離的な近さがかなり予測に役立っていると考えられます。

※(上図で説明が付いていない)既存の説明変数について、1日の観測回数、最小値、中央値、最大値、分散の
変数名の接尾語として、それぞれ”_cnt”, ”_min”, ”_mid”, ”_max”, ”_var”が付いています。
例えば、”co_mid”はCOの中央値を表しています。
※既存の説明変数の国名、都市名、緯度、経度は説明変数から除外しています。
②データ加工
モデルの精度を改善するために、不要なデータを除外するなどのデータ加工を実施しました。
1. テストデータの都市から遠い都市のレコードを学習データから除外
テストデータの都市が含まれないエリアのレコードを学習データから除外
→距離が遠い都市のレコードを除くことにより、ノイズが減ったため精度が改善したように思います。
2. 不要になった説明変数を除外
除外した説明変数:国名、都市名、緯度、経度
→場所に関する説明変数をエリア関連の変数のみに絞ることにより、ノイズが減ったため精度が改善したように思います。
3. スタッキング用データを作成
学習データから以下のように5foldでスタッキング用データを作成しました。
モデリングの際に、学習に使用する部分でモデルを作成して、検証に使用する部分でスコアリングすることにより、リークしないように元の学習データにモデルの予測値を付与することができます。
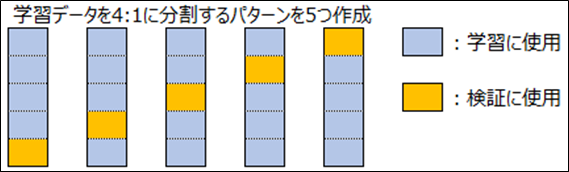
学習と検証の分け方につきまして、同じ都市の中で層別サンプリングして、学習と検証の両方に同じ都市のレコードが含まれるように作成しました。
※この方法は同じ都市のレコードは学習か検証の一方にしか含まれないようにするGroupKFoldではありませんので、検証データでの精度がテストデータの精度より良くなってしまう傾向があります。実務でモデルを作成する際など、より正しく検証したほうが良い場面ではGroupKFoldの方が望ましいと考えられます。ただし、今回のように極端に大きい値を持つ都市が存在する場合、GroupKFoldではその都市が学習か検証に偏在するので、K個のモデルの安定性が損なわれる可能性があります。(今回の場合、比較していませんので、どちらが良かったかは不明です。)
③モデリング
今回の解法では、モデリングとしてスタッキングを使用しました。
構造としては、以下のような2段階の比較的シンプルなものになります。
1段階目:ベースモデルを複数作成
2段階目:ベースモデルの予測値を説明変数にしたスタッキングモデルを複数作成
1. ベースモデル作成
前述の5foldのスタッキング用データに対して5つのモデルの予測値を作成しました。
モデルと検証データのRMSE([]内)と主なハイパーパラメータは以下になります。
(I) CatBoost [18.851]
・iterations=3000, depth=10, cat_features=[‘Area’], use_best_model=True
(II) LightGBM [18.880]
・params = {‘metric’: ‘rmse’, ‘max_depth’: 9, ‘learning_rate’:0.02, ‘numleaves’:200}
・categorical_feature=[‘Area’], num_boost_round=15000, early_stopping_rounds=500
(III) Neural Network(隠れ層2つ) [21.581]
・MLPRegressor(hidden_layer_sizes=(100,100,),alpha=0.0001)
(IV) Neural Network(隠れ層3つ) [22.011]
・MLPRegressor(hidden_layer_sizes=(100,100,100,),alpha=0.0001)
(V) Random Forest [20.446]
・min_samples_leaf=3
モデルの多様性を考慮してツリー系のモデルとニューラルネットワークを併用しています。
テストデータへのスコアリングの際は、1種類のモデルにつき5つの予測値を平均します。
2. スタッキングモデル作成
ベースモデルの予測値を説明変数に用いてスタッキングモデルを作成します。今回の解法では、学習データを(II)LightGBMの予測値をもとに以下のように4つの部分に切り分けて、それぞれについてスタッキングモデルを作成しました。
(i) LightGBMの予測値>250
→RandomForestを除く4つの予測値を説明変数として、Ridgeモデル作成
(ii) LightGBMの予測値<=250
→RandomForestを除く4つの予測値を説明変数として、Ridgeモデル作成
(iii) LightGBMの予測値が65~140
→RandomForestを含む5つの予測値を説明変数として、Ridgeモデル作成
(iv) LightGBMの予測値<=65 かつ 5つのベースモデルの予測値の標準偏差<3.0
→RandomForestを含む5つの予測値を説明変数として、Ridgeモデル作成
テストデータへのスコアリングの際にも同様の条件で切り分けて、それぞれのモデルを適用します。
このとき、(ii)と(iii)(iv)で範囲に重複がありますが、(iii)(iv)を優先して適用します。
●この方式を採用した背景
・学習データの全部のレコードを使用したスタッキングモデルとベースモデルのLightGBM単体の予測値の検証データでのRMSEを比較したところ、値が250未満のところではスタッキングモデルのほうが良く、値が250以上のところではLightGBMのほうが良くなっていました。このことから、値が大きいところと小さいところではベースモデルのより良いミックスの方法が異なると考えられるので、学習データを値の大きさで分割してモデルを作成することにしました。
・RandomForestは値が大きいところで精度が著しく悪くなっていました。そのため、値が小さいところでのみスタッキングモデルに組み込むことにしました。
・RandomForestは値がかなり小さいところでは、そのまま組み込むと精度が悪化してしまいましたが、ほかのベースモデルの予測値と近い場合のみ組み込むことにより精度が改善しました。
④テストデータの予測値の補正
テストデータの特定の3都市について、一部の日付や期間で予測値が実績値を大きく外していると思われるため、その部分の予測値を補正しました。
まず、RMSEのところで既述したように値が大きいレコードでの正確性が重要になるので、テストデータの予測値の大きさを都市ごとに確認しました。
テストデータの都市ごとの予測値の平均値(降順)

→テストデータの都市の予測値と周辺の都市の実績値などを比較して、今回は
・インドのGhāziābād
・インドのNagpur
・ボスニアヘルツェゴビナのSarajevo
の3都市について予測値が外れていると思われる部分を発見したため補正しました。
1. インドのGhāziābādの予測値の補正
GhāziābādはPM2.5がトップクラスに大きいレコードを持つ学習データの都市デリーの近郊にある都市です。

Ghāziābādの予測値の推移は以下のようになっていました。(横軸:日付、縦軸:PM2.5)

デリーの実績値の推移は以下のようになっていました。

この2つを比較すると、デリーの実績値には400超の外れ値が存在しますが、Ghāziābādの予測値は大きくても350程度になっていることがわかります。このことから、Ghāziābādの予測値はデリーが大きな値の日付では小さすぎる可能性が高いと考えました。そのため、デリーが大きい値(315以上)かつGhāziābādの予測値が外れ値でありそうな場合(Ghāziābādの予測値と2番目に近い都市の実績値がそれなりに大きい場合)、Ghāziābādの予測値にデリーの実績値を代入しました。
2. インドのNagpurの予測値の補正
NagpurはPM2.5が比較的大きいインドの内陸部にある都市です。

Nagpurの予測値{オレンジ線}と
1番目に近い都市Bhopalの実績値{青線}と
2番目に近い都市Hyderabadの実績値{青線}
の推移は以下のようになっていました。

赤線はPM2.5が150の線で、緑線の間の期間は2020/11~2021/02になります。
緑線の間の期間で、1,2番目に近い都市では150付近の実績値が多いことに比べて、Nagpurの予測値は平均的に150より小さくなっていて、予測値が過小評価されている可能性が高いと考えました。そのため、上記の期間内の予測値が中くらいの大きさ(緑色の点線の間[70~140])である場合、予測値を一律に+25しました。
3. ボスニアヘルツェゴビナのSarajevoの予測値の補正
Sarajevoは東欧の都市で、その周辺の地図は以下のようになっています。

Sarajevoの予測値{オレンジ線}と
近くの都市Nišの実績値{青線}と
近くの都市Nišでの残差(=実績値-予測値[LightGBM]){赤線}
の推移は以下のようになっていました。

Sarajevoの予測値とNišの実績値の推移は比較的似ているようですが、Nišの残差の推移を見ると、緑線の間の期間(2020/10~2021/03)で残差が平均的に0(灰色の横線)より大きくなっていることがわかります。このため、Nišではこの期間で予測値が実績値より小さくなる傾向があるため、Sarajevoの同期間の予測値も過小評価されている可能性が高いと考えました。そのため、上記の期間内の予測値が中くらいの大きさ(緑色の点線の間[70~130])である場合、予測値を一律に+20しました。
※1,2番目に近い都市ではなくNišと比較している理由は1,2番目に近い都市は上記の期間内のレコードが少ないためです。
■結果の推移
今回のコンペを取り組む過程で採用した手法と投稿ファイルのPrivate LBのスコアの推移は以下のようになりました。今回実施した特徴量エンジニアリング・スタッキング・予測値の補正のそれぞれで効果がありました。

※Ghāziābādの予測値補正により改善した分のスコアは約0.075でした。
最終結果として、Private LB上での順位は6位でしたが、上位者の失格・辞退のため確定順位は4位となりました。
https://signate.jp/competitions/624/leaderboard
■考察など
・空間的な類似性を捉えるための特徴量として、1,2番目に近い都市と同じエリアのPM2.5を作成しましたが、1~3位の方の解法を拝見したところ、もう少したくさんのパターンで作成すると精度が良くなるようでした。例えば5番目以内に近い都市のPM2.5や一定距離以内の都市のPM2.5を追加することがよさそうです。
・今回の解法では、テストデータの予測値を直接補正している部分がありますが、モデルとしての汎用性がなくなってしまうので、実務等で使用することは望ましくありません。今回の予測値の補正はほかの時季に比べて冬の時季でPM2.5が大きくなっているところで行っているので、季節性の変動を捉える特徴量を追加することで改善する可能性がありそうです。例えば30日間のPM2.5の移動平均を作成することが考えられます。
・今回の場合、予測値の補正をしなくても特徴量エンジニアリングやスタッキングを工夫することで銀メダルの水準に届きました。少しずつでも工夫することによってメダル圏内に食い込めることもありますので、興味のある方はぜひいろいろなコンペに参加して工夫して楽しんでいただけたらと思います!



コメント