






NI BLOG
ネイチャーインサイト株式会社の情報発信ブログ
SASに関する技術情報など






SIGNATEのデータ分析コンペに 新卒1年目で銀メダルを獲得することができました
あいさつ
初めまして、新卒1年目のikedaと申します。
この度、2023/12/1~2023/1/8に開催された下記のSIGNATEのデータ分析コンペにて、21位(銀メダル/874人投稿)をとることができました。
SMBC Group GREEN×DATA Challenge 木の健康状態を予測しよう!
https://signate.jp/competitions/1247
この記事では、コンペの解法やモチベーションをご紹介することを目的として、以下の内容について記載いたします。
・今回の取り組みの目的
・コンペの目的、背景
・実施した解法
・結果
ここで紹介する解法は、基本的なものが多いと思います。コンペ初心者の方、そろそろ挑戦しようと思っている方の参考になれば幸いです。
今回の取り組みの目的
主な目的は以下の2つになります。
・研修で学んだことをアウトプットしたい
・コンペの流れを理解したい
私はデータ分析に関して約3ヶ月間の研修を受けました。機械学習やプログラミングの経験がそれまでほとんどなかったため、この研修で学んだデータ分析の技術や理論を、実際に自分自身で使ってみることが今回の大きな目的になります。
コンペの目的、背景
1. コンペの問題設定
今回のコンペの目的は、木の大きさ、潜在的な問題点、周辺環境などの定量および定性データを基に、「木の健康状態」を「悪い」「普通」「良い」の3種類に分類して予測することです。
2. 評価指標
評価指標はMeanF1Scoreといって0~1の値を取り、大きいほどいい指標となります。
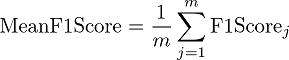
3. データの内容
学習・テストデータについての内容は以下のようになっています。
レコード数
学習データ:19984件
テストデータ:19702件
データの粒度:木ごと
目的変数:木の健康状態(「悪い」「普通」「良い」の3種類)
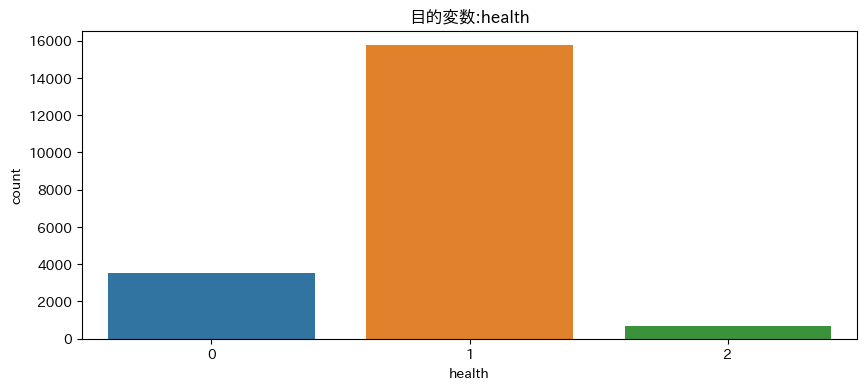
この目的変数が今回の分析の中で特に問題となっています。その理由は、下記の棒グラフのように、各カテゴリーの割合が大きく偏っていることにあります。具体的な割合は以下の通りです。
0(普通):17.7%
1(良い):78.8%
2(悪い):3.5%
さらに注意すべき点は、最も良い評価が「1」とされており、カテゴリーの序列が一般的な順序とは異なっていることです。
説明変数:木のサイズ、年月日、木の立地、データの記録者、木に関する問題、木の名前
※外部データは今回、使用していません。
データについての留意点:
・学習データとテストデータを比較した際、それぞれで含まれるカテゴリ値に差分がないことが分かりました。また、カテゴリーの割合や数値の分布が非常に似ていることが確認できました。
例として、下記に木の位置を5つのカテゴリーに分けた変数の表を示します。これを見ると、両データセット間の分布の類似性がより理解しやすくなると思います。
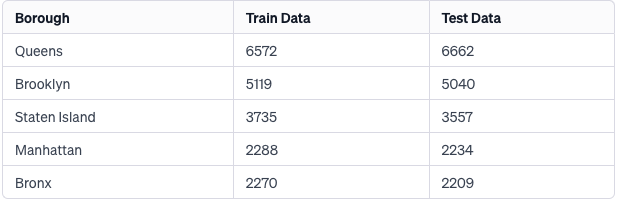
学習データとテストデータは、期間に関しても同じです。
実施した解法
1. 特徴量エンジニアリング
新たな特徴量の作成は行いませんでした。正直なところ、作成することができなかったのです。木の健康についての考察も試みましたが、加えた変数が逆に精度を下げる結果に終わってしまいました。
私が考えた特徴量の一部を下記に挙げておきます。
・45個に分けられた地区をターゲットエンコーディング
・気候の影響を考慮して、日付から月の部分のみを抽出し、それをカテゴリとして変換した
他の上位入賞者の解法を見てみると、私には思いつかなかった特徴量の作成が見受けられました。
・各日付を中心に、その前後の4日間のデータの平均をとる
・日付からweekofyear(1年を54分割)を計算してカテゴリ変数
季節性を考えるなら上記のようにもっと粒度を細かくするべきでした。このようなアプローチの細かな違いの積み重ねが結果に影響を与えたのだと思います。
2. データ加工
不要となった説明変数を除外
正式名称と略称のように完全に相関している説明変数を3つ除外しました。
欠損値補完
データセットには3つの説明変数に欠損値が含まれていました。
これらの説明変数に焦点を当ててみると、例えば木を保護するためのガードの種類に関連する変数(guards)で、ランダムに発生している欠損値はでなく、「ガードがない」という意味が読み取れる欠損値と判断しました。そこで、これらの欠損値に対して「missing」という値を補完することにしました。この欠損値処理をした変数「guards」を利用することによってモデルの精度が向上したので、モデルに採用することに決定しました。
一方、残りの2つの変数は、欠損値を補完した後にモデルの精度が低下してしまったため、これらは欠損したままの状態で扱うことにしました。
3. モデリング
クロスバリデーション(CV)Stratified K-Foldの5分割を採用しました。この方法では、各分割でデータセットが均等に分散され、各カテゴリーの割合が全体のデータセットとほぼ同じになるようにしています。Stratified K-Foldは、特にクラス不均衡のあるデータセットにおいて効果的です。
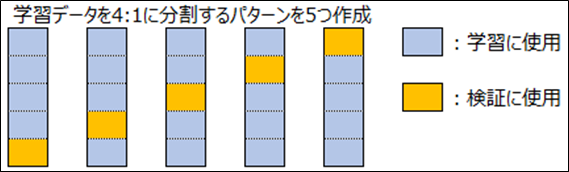
モデル
今回の解法では、LightGBMを用いたマルチクラス分類問題として解くのではなく、2値分類を2回に分けて行う方が精度が高かったため、この方法を採用しました。
具体的には、まず「1(良い)」と「それ以外」を分類し、次に「0(普通)」と「2(悪い)」を分類しました。こうすることで、特定のクラス間の識別を改善するために、特徴量の選択やパラメータの調整を各ステップで別々に行うことができるため、より柔軟なモデリングが可能になります。
閾値
今回の分析で、trainデータとtestデータを比較した結果、両者が非常に似たデータ構造を持っていることが明らかになりました。このことから、testデータにおける木の健康状態(health)の分類も、trainデータと同様である可能性が高いと推測しました。そのため、0(普通)、1(良い)、2(悪い)の各カテゴリーの予測割合をあらかじめ決めるにしました。
具体的な方法としては、先に作成したStratified K-Foldクロスバリデーションを用いて、予測結果を正例・負例(二値)に分類するための基準点である閾値(threshold)をグリッドサーチしました。このプロセスにより、最適な割合を特定し、それをモデルの訓練に適用しました。
結果
1. 最終順位の出し方
コンペ中は、評価用データセットの一部に基づいて、参加者の暫定順位がパブリックリーダーボード(暫定のランキング表)に表示されます。コンペ終了時には、パブリックリーダーボードに使われなかった残りの評価用データで最終的なスコアを算出し、プライベートリーダーボードによって最終順位が決まります。要するに、進行中のスコアはあくまで暫定的なものとなっており、最終的な順位は最後の瞬間までわからないということです。
2. 結果発表

最終結果、私の順位は約70位から一気に21位にジャンプアップしました!
どうやらコンペに参加した多くの人々の順位も大きく変動したようです。この順位の変動は、先に述べたパブリックリーダーボードとプライベートリーダーボードのスコアの違いに起因しています。
ここで大事になってくるのがクロスバリデーション(CV)です。コンペで勝つには「Trust your CV(自分のスコアを信じろ)」と言われてるらしいのですが、その通りでした。多くの人たちがシェイクダウンが起きた理由は、プライベートリーダーボードだけで、自分が作ったモデルの精度を評価していたことです。私の場合、幸いにも自分のCVの結果を信じることができ、それが順位につながりました。
最後に
今回の結果は、3か月間ひたすら分析の基礎固めを0から指導していただいた研修のおかげです。研修に携わっていただいた先輩方、そして一緒に苦楽を共にした同期に感謝を伝えたいです。ありがとうございます!
また、この1か月は、コンペの取り組み方や、モデル構築の仕方、精度向上の考え方など非常に学びの多く充実した期間でした。その中で上手くいかなかったことも多々ありましたが、一人の力でメダルを獲得できたことは大きな自信につながりました。
これからもどんどんコンペには挑んでいき、今度はゴールドが取れるようにがんばりたいと思います!


コメント