






NI BLOG
ネイチャーインサイト株式会社の情報発信ブログ
SASに関する技術情報など





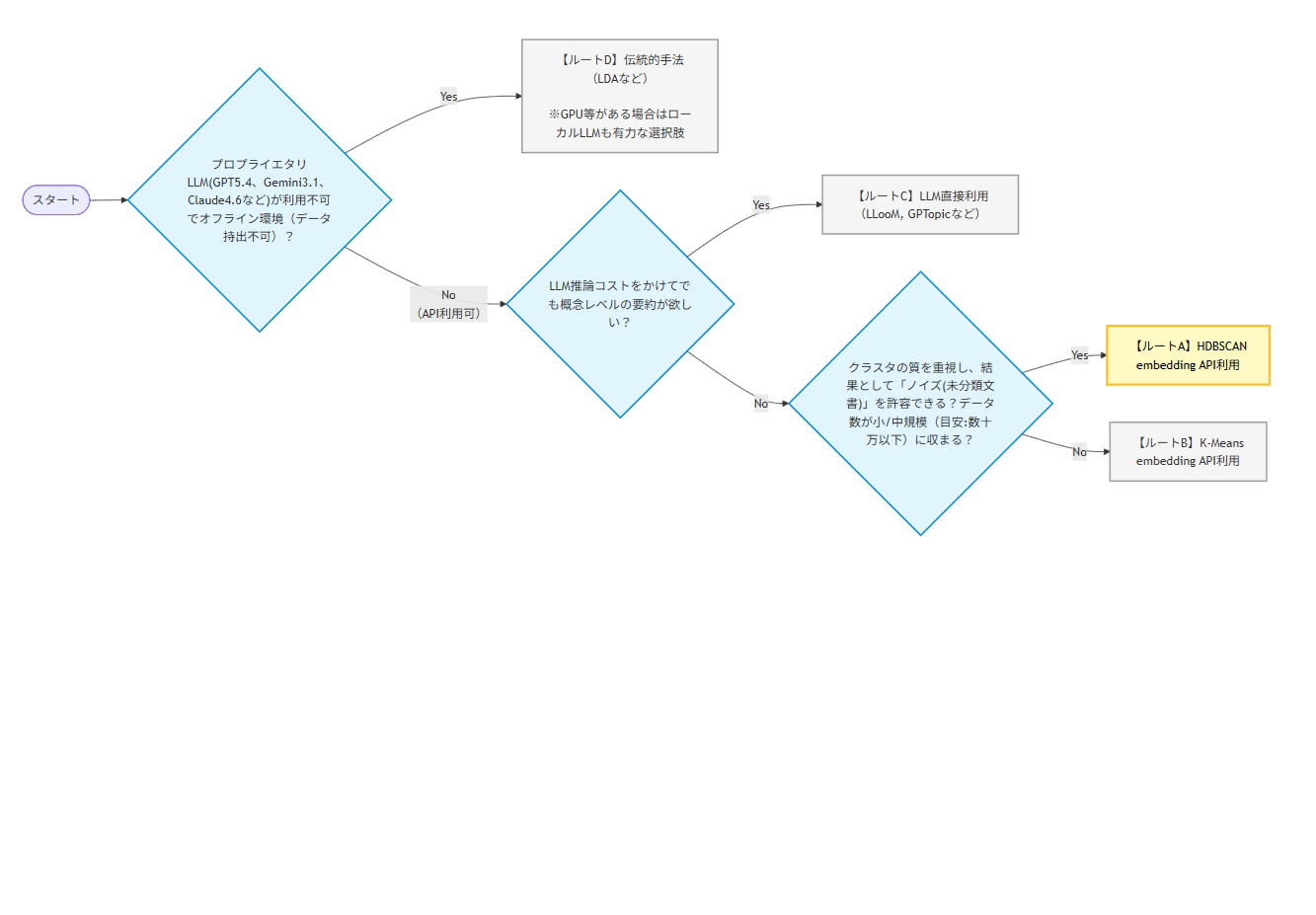
Databricksダッシュボードのポイント解説
はじめに
ご無沙汰しております。データサイエンティストの池田です。
気づけば3年目に入りました。時間が経つのは本当に早いものですね。積もる話もありますが、今回は早速本題に入りたいと思います。
突然ですが、Databricksのダッシュボードを使ったことはありますか?
ここ最近、業務で使用する機会があったのですが、意外とダッシュボードについてまとめてる人もいなそうでした。そこで今回は、初めてDatabricksのダッシュボードを開発する人に向けて、主な挙動の流れと、便利な3つの機能(パラメータ、カスタム計算、クロスフィルタリング)に絞って、できるだけ簡潔に解説します。お役に立てれば幸いです。
また、本記事の内容は執筆時点(2025年10月10日)の機能に基づく説明です。
Databricksのダッシュボードとは
Databricks上にあるデータを直接使い、集計値やグラフを用いて直感的に可視化できる機能です。
これにより、データを外部BIツールへ移動させる手間が不要となり、常に最新の状態でデータを確認できます。
主な挙動の流れ
ダッシュボードがどのようにデータを読み込み、表示するデータを作成するかを説明します。
作成までの流れは以下の通りです。
| フェーズ | 主な挙動 | 説明 |
|---|---|---|
| ① クエリ実行前 | パラメーターが定義される | クエリ実行前に、クエリに動的な値が挿入され、クエリが定義されます。 |
| ② クエリ実行 | データセットが作成される | ダッシュボードで使用するデータセットを作成します。また、クエリはデータの参照(SELECT)のみです。 |
| ③ クエリ実行後 | フィルターの適用 ー>カスタム計算の適応 |
作成されたデータセットに対してフィルターをもとに絞り込み後、カスタム計算を行います。 |
ここからは、上に出てきた機能(パラメータ、カスタム計算、クロスフィルタリング)について解説をしたいと思います。
パラメータ
ダッシュボードの「パラメーター」とは、日付や製品カテゴリなどの条件を、クエリ実行時に動的に指定する機能です。SQLクエリが実行される前にあらかじめ不要なデータを除外してから集計を行うため、データベースへの負荷が減り、結果の表示を高速化します。
例えば、日付範囲を指定して使用します。
ユーザーがカレンダーで期間を選ぶだけで、その期間のデータだけを読み込み、表示できます。
SELECT *
FROM sales.daily_summary
WHERE sales_date BETWEEN :date_param.min AND :date_param.max;パラメーターのデータ型
文字列、数値、日付、日付範囲など、様々なデータ型を選べます。
フィルターとの使い分け
- パラメーターを使う時:
- 巨大なデータに対し、日付範囲など大きな条件で先に絞り込み、初回表示を速くしたい場合
- フィルターを使う時:
- ある程度の規模のデータセットを取得した後で、ユーザーに様々な角度から自由にデータを探索させたい場合
カスタム計算
SQLを書き直さなくても、すでにあるデータセットを元にダッシュボード上で新しい計算列や指標を追加できる機能です。
カスタム計算のメリット
- データセットを再利用:
- 元のSQLを変更せずに、可視化ごとに必要な指標や値を追加できます。
- 条件を変えながら柔軟に分析可能:
- フィルターやパラメーターを切り替えると、カスタム計算の値も自動で再計算されます。
- 粒度を自動変更:
- 可視化側の集計単位(月単位・商品単位など)に応じて自動的に計算してくれます。
カスタム計算の2つの種類
| 種別 | 説明 | 例 |
|---|---|---|
| 計算メジャー | 総売上高や平均コストなどの集計値を作成 | TRY_DIVIDE(SUM(price), SUM(cost)) |
| 計算ディメンション | 年齢範囲の分類などの集計軸を作成 | CASE WHEN age >= 18 THEN ‘成年’ ELSE ‘未成年’ END |
注意点
- ウィンドウ関数などは使えません。
- 1つの式にメジャーとディメンションは混ぜられません。
クロスフィルタリング
あるグラフの一部をクリックすると、その値がフィルターになり、他のグラフも連動して絞り込まれる機能です。一つの操作で複数の可視化が連動するので、スムーズな分析が可能になります。
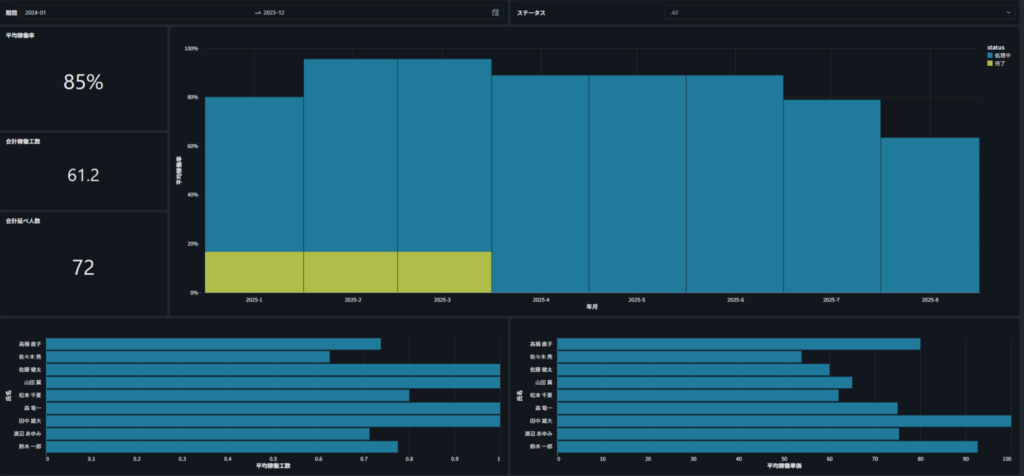
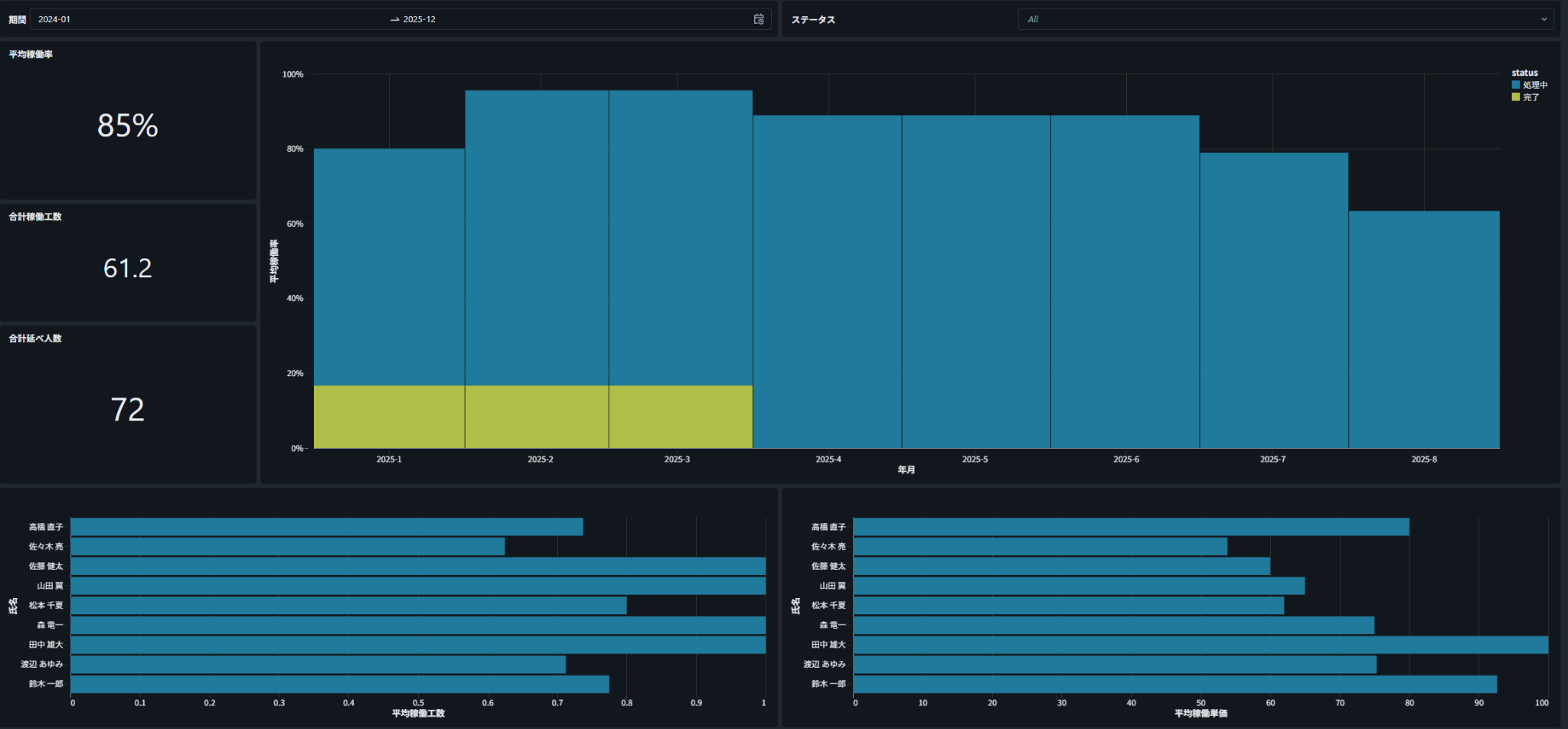
例えば、下の棒グラフで「特定の担当者」をクリックすると、
すべてのグラフが連動し、クリックした担当者に関するデータだけが表示されます。
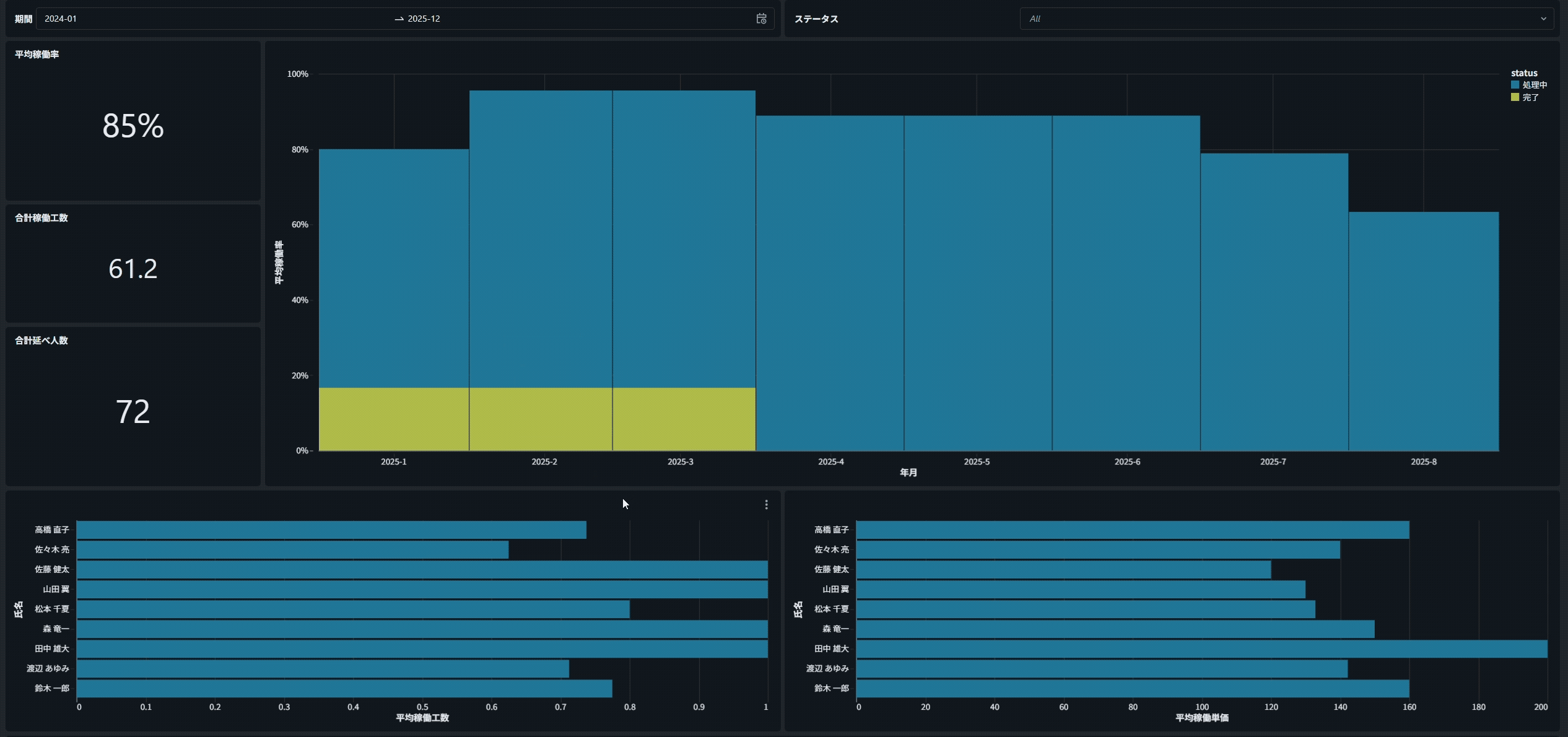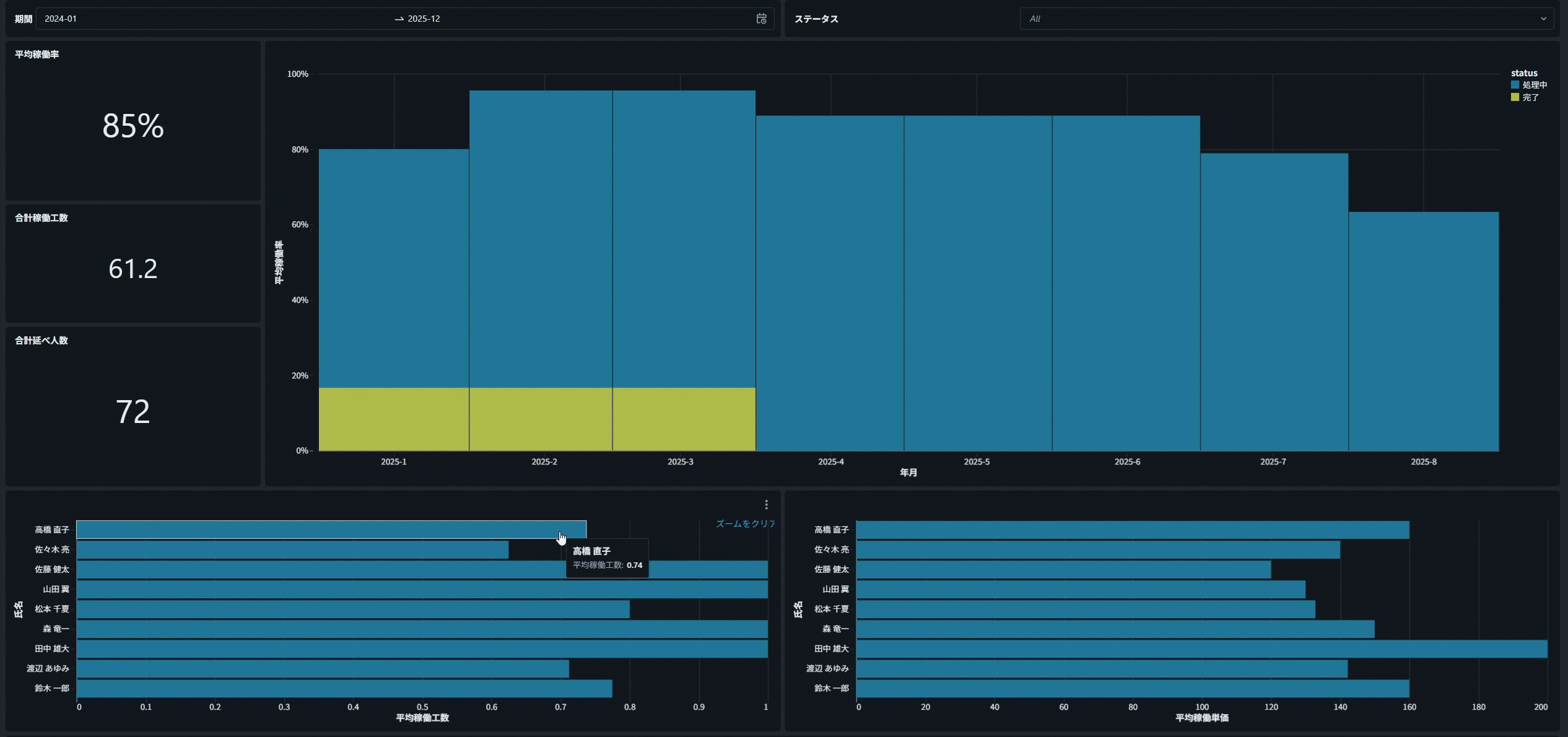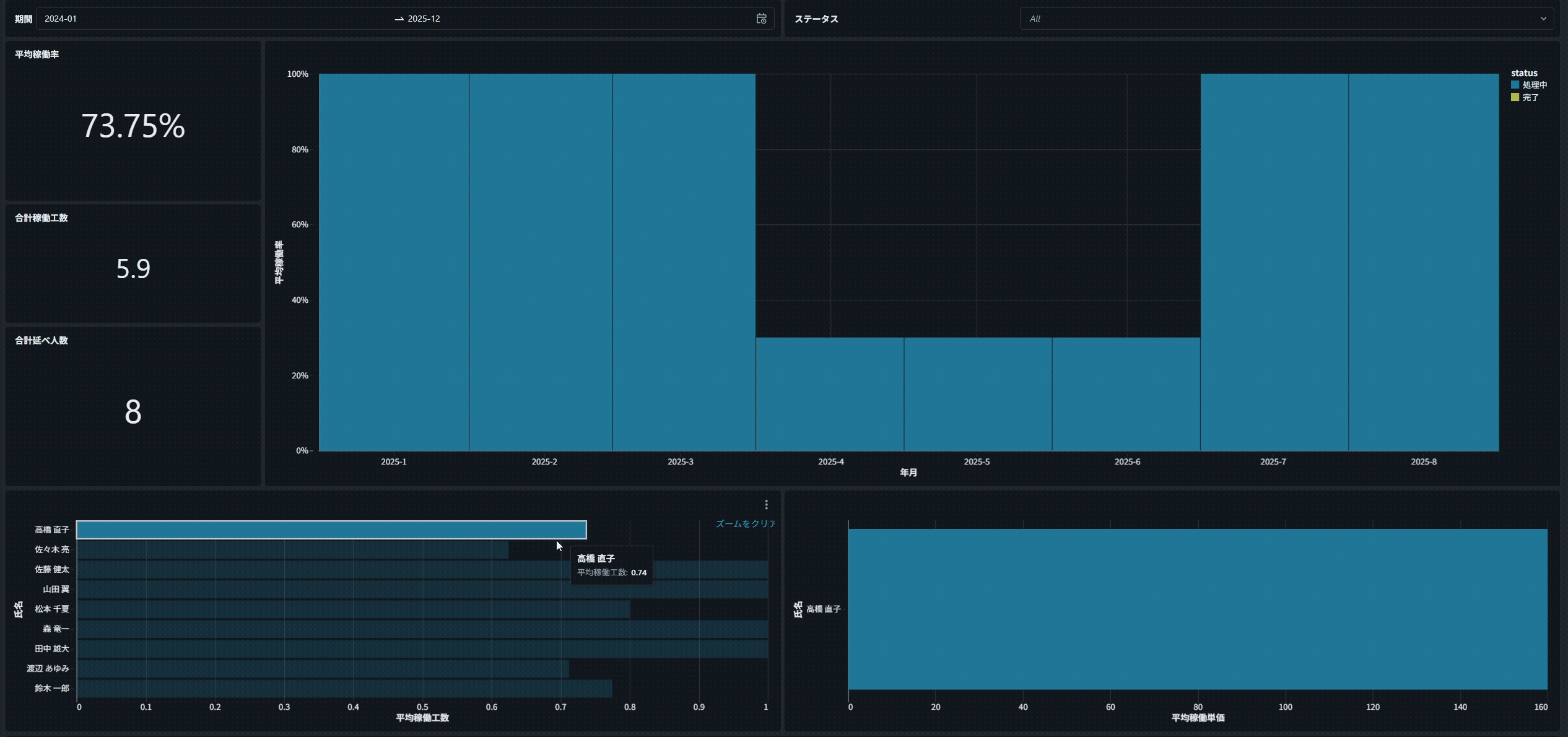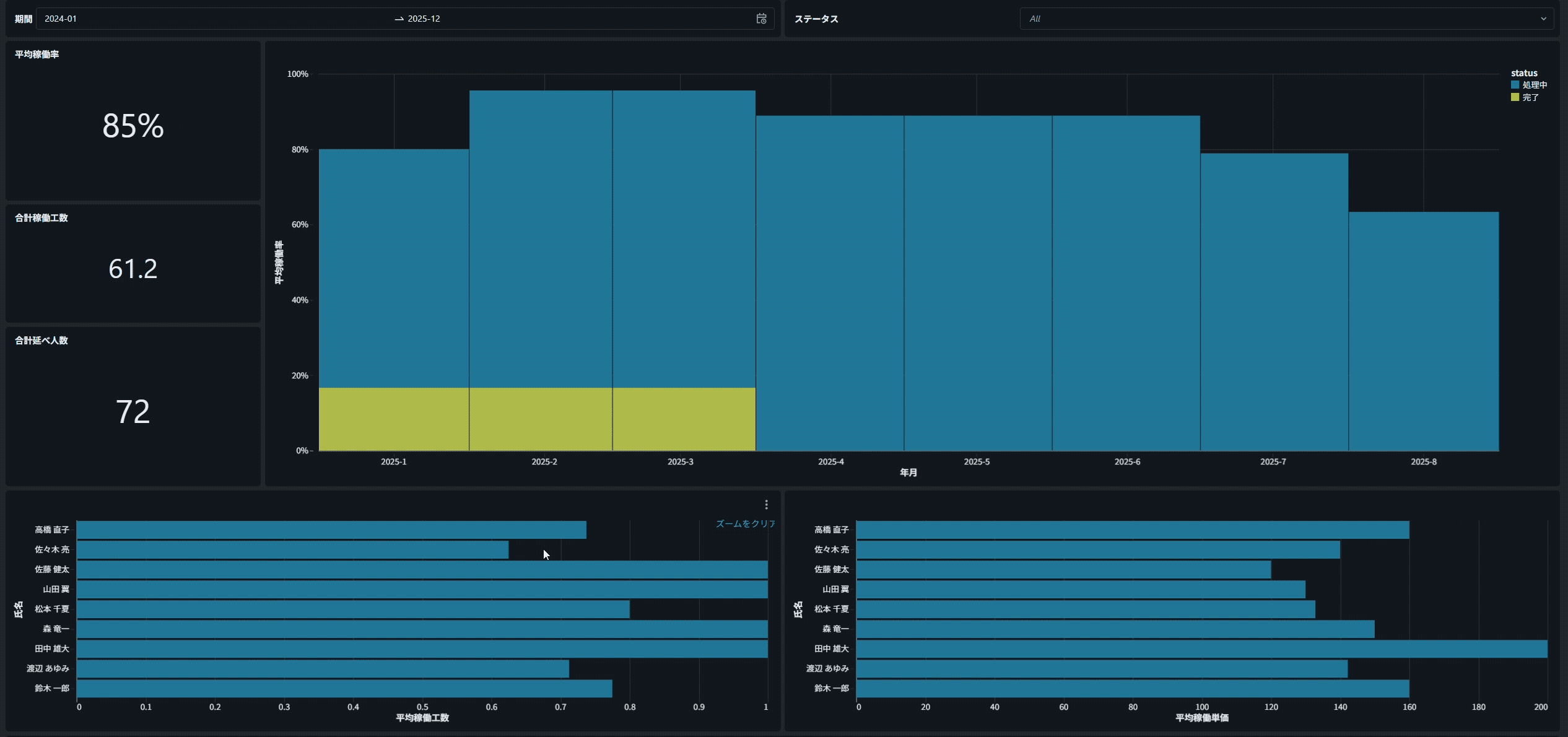
注意点
- クエリ実行後のデータセットに対して適用されます。
- 同じデータセットを使っているグラフ同士でのみ有効です。
- グラフの種類によっては対応していない場合があるので注意が必要です(例: 折れ線グラフ)。
まとめ
Databricksダッシュボードの基本構造と、つまずきやすい3つの機能パラメータ・カスタム計算・クロスフィルタの3つを解説してみました。最新情報や詳細について気になる方がいれば、下の公式ドキュメントをご確認ください。
最後まで読んでいただきありがとうございました!
参考にした公式ドキュメント
- フィルター: https://docs.databricks.com/dashboards/filter-types
- パラメーター: Work with dashboard parameters – Azure Databricks | Microsoft Learn
- カスタム計算: https://docs.databricks.com/dashboards/datasets/custom-calculations
- クロスフィルタリング: https://docs.databricks.com/dashboards/



コメント