






NI BLOG
ネイチャーインサイト株式会社の情報発信ブログ
SASに関する技術情報など





LLMの社内勉強会を開催しました!
LLMの急速な発展
ChatGPTの登場からはや1年、最近LLMの話題をどこでも聞くようになり、各社ともに研究や開発が活発になってきています。
弊社でも興味のあるメンバーが多く、社内有志メンバーの空いた時間を用いて、LLMを使ってどんなことができるかを試しています。
今回は、先日実施したLLMの社内向け勉強会について報告します。
勉強会の内容
LLMの勉強会は座学編とハンズオン編を実施しましたが、この投稿では、座学編でどんな内容を実施したかを書いていきます。
座学編はD.Aさんにお願いをしまして、下記の内容を発表していただきました。
1. はじめに
2. LLM誕生までの経緯
3. LLMの活用領域
4. LLMの弱点と克服方法
5. LLM活用の現在地点(業界動向)
100Pを超える資料を作成していただき、詳しく、わかりやすく発表していただきました!
内容をすべてを載せるとかなり膨大となってしまうので、要点をピックアップして紹介します。

1. はじめに
座学編のゴールは、LLMに関する前提知識を共有し、「会社/コンサル部として、今後LLMとどう関わるべきか?」についてディスカッションすることでした。
そこで、まずは生成AIやLLM関連の用語に慣れていない方に向けて、LLMの説明で頻出する用語について説明していただきました。
説明した用語の例
・Generative AI(生成AI)
・LLM
・AGI(汎用人工知能)
・Prompt
・Completion
・Embedding
・などなど
個々の用語は何となく聞いたことがありますが、ここでしっかり定義することで、勉強会の説明内容がわかりやすくなりました。


この章の最後のまとめとして、下記のことを話していただきました。
・ChatGPTをはじめ、各種LLMの登場は、AGI実現が現実味を帯びてきた?と 多くの人(非開発者含む)に感じさせるエポックメイキングなできごとだった
・ビックテックはLLM開発/活用にビジネスチャンスを見出しており、LLM活用サービスのデファクトスタンダード競争に勝つために巨額投資している
・仕事/生活に身近なサービスとなったら、弊社のビジネスにも大きな影響があり得る
LLMや生成AIの可能性については方方で言及されていますが、やはり大きなビジネスチャンスやリスクになりうるということは私も強く思っているところです。
2. LLM誕生までの経緯
この章では、GPT4が誕生するまでの自然言語処理技術の変遷について解説していただきました。
基礎のBag-of-Wordsからはじまり、word2vec、RNN、Transformer、BERT、Scaling Lawなど、重要なモデルや概念を紹介されていました。
さらに、LLMの重要な精度改善(パラメータ更新)手法についても説明していただきました。
Fine Tuning…
事前に訓練されたモデルの一部または全体を、新しいデータセットで追加学習すること。
LLMでは、自然言語処理のモデルを新たに学習して変更したい場合に用いる。
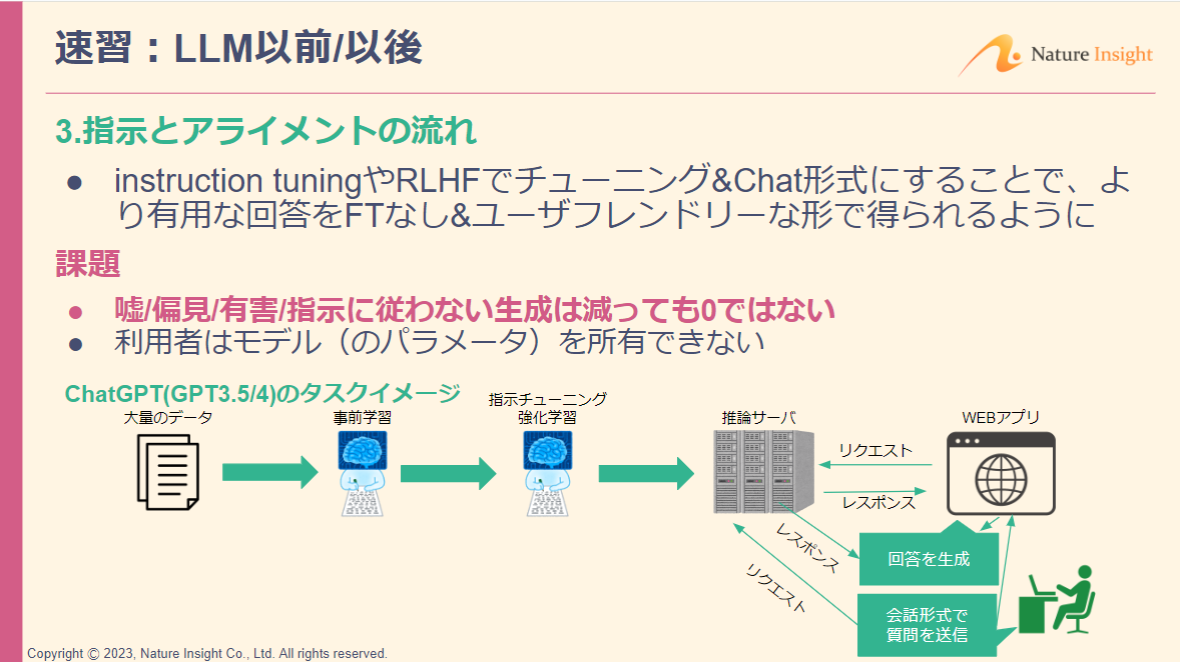
Instruction Tuning …
事前学習済みの言語モデルに対し、何らかの指示(「以下の文を要約せよ」など)に従うようにFine Tuningを行うこと。
3. LLMの活用領域
LLMの活用領域として、下記のような領域で活用できる可能性を話していただきました。
・検索の代替
・相談相手(チューターやカスタマーサポートなど)
・プログラミングのサポート、翻訳、校正
・コンテンツ(文章・画像・動画)の生成、アイディアの列挙
・プログラム生成・データ拡張
さらに、業務に関連しそうな領域では、具体的な製品・サービスも紹介されていました。
すでにプログラミング領域では「github copilot」や「Jupyter AI」などのサービスが提供されています。
やはり、データ分析領域でも、今後、仕事の進め方が大きく変わる可能性があります。
これは仕事が奪われるという意味ではなく、LLMを活用することにより大きな利益を生み出すことができるということではないかと思います。
この潮流に乗り遅れないように、少なくとも私たちはLLMを使える状態にはしておきたいところです。
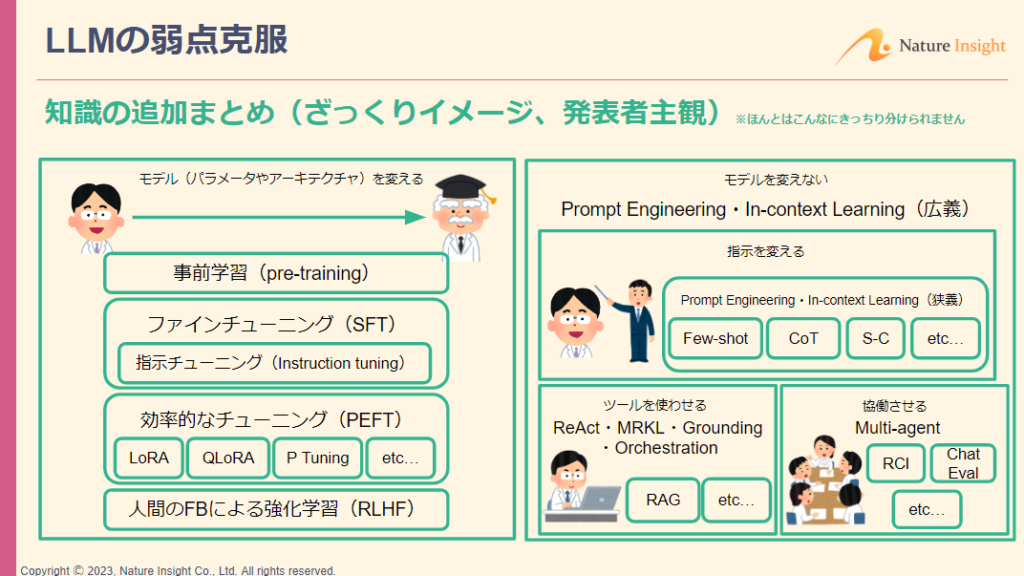
4. LLMの弱点克服
今まではLLMの便利さについて話していただきましたが、LLMのモデルにも弱点は多いです。

※注:勉強会資料は2023年10月時点までの情報で作成しています
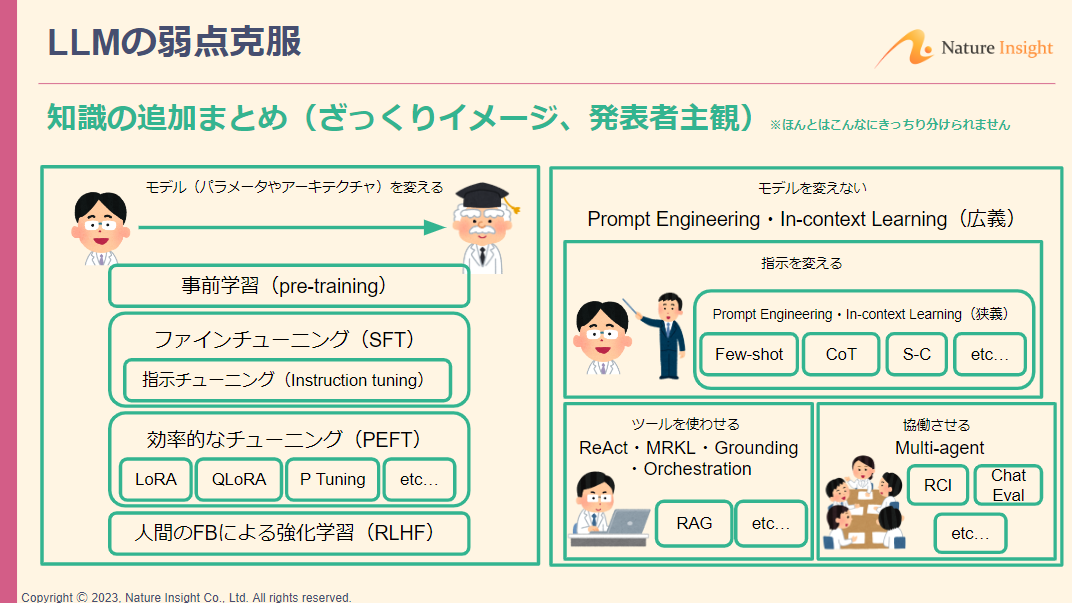
特にHallucinationやtraining cutoff、倫理的に有害な出力はよく出てくる問題で、これを克服するために、「知識の追加」や「ふるまいの制御」などを実施します。
「知識の追加」には、下記のようなアプローチ方法があります。
・より性能の良いモデルを選定/作成する:事前学習
・モデルを改良する:ファインチューニング
・よりよい指示を出す:プロンプトエンジニアリング
このうち、プロンプトエンジニアリングには下記のような手法があります。
・数件例示をして答えさせる:Few-shot
・回答に至る考え方(思考の連鎖)をプロンプトで誘導する:Chain of Thought
・検索結果をプロンプトに埋め込む:Retrieval Augmented Generation(RAG)
勉強会では、上記のほかにも様々な手法や、LLMの「ふるまいの制御」の考え方(責任あるAI)について紹介していただきました。
5. LLM活用の現在地点
この章では、LLM活用の現在地点として、以下のような業界動向について話していただきました。
・ローカルで実行(パラメータ所有)できるオープンソースLLM(llama2など)の現状
・検索で独自ナレッジや最新情報を追加できるRAGの重要性
・LLMの進化や最新研究の方向性
・LLM開発関連フレームワークやプラットフォームの動向
LLMや生成AIは流行っていますが、実際に商用サービスとして運用しようとすると、弱点の克服や責任範囲のコントロール、技術の進化スピードの速さなどの観点から、課題がたくさんあります。
LLMや生成AIを社会実装していくためには、会社として/コンサル部としては何ができるのか、何をすべきかを考えていかなければいけないときが来ていると感じました。
勉強会の実施後
以上の勉強会を踏まえて、参加したメンバーでLLMとの関わり方について、以下のそれぞれの視点で議論しました。
・サービスの利用者として
・モデルの調教者として
・モデル/サービスの導入者として
・サービスの開発者として
・研究者として
現状ではサービスの利用者視点の意見が多かったですが、今後は何らかのサービスを提供する側にもっていきたいです。
この勉強会を通じて、部のメンバーには、LLMに対する理解や課題意識は十分持っていただいたと思います。
今回紹介した座学編のみで終わらず、その後は実際に獲得したLLM案件で得た知見の共有会や、Azure OpenAIを用いたハンズオンを実施しました。
最後に
LLMや生成AIは発展スピードが速いので、この技術に乗り遅れずについていけるよう日々勉強していきたいところです。
読んでいただきありがとうございました!


コメント